The enterprise data warehouse (EDW) is a fairly new entrant into the universe of databases mainly optimized for reading operations. By structuring data in a rigid schema, EDWs accommodate the need of data analysts to deliver decision-supporting insights.
This article elaborates on the rise of the data warehouse and highlights recent evolution and trends.
From OLAP cube to data warehouse
Traditionally, databases were associated with the storage and management of data and mainly used by IT professionals. These are workloads known as online transaction processing (OLTP).
But it didn’t take long for business professionals to come up with use cases for that same data, often in the realm of strategic and managerial decision-making.
However, analytical workloads had to be separated from operational workloads to ensure that these business users couldn’t break the database. Moreover, these users were less interested in inserting and updating data. Instead, their sole focus was on reading data from the database.
This database usage pattern is known as online analytical processing (OLAP) and has sparked the rise of a software category known as the OLAP cube.
OLAP cubes
In the early days of computing, where you couldn’t just borrow some resources in the cloud, OLAP cubes served as the best tool to serve data in a memory-efficient form optimized for typical analytical operations, such as subsetting and aggregating. Thus, you can think of it as a bunch of nested arrays that are carefully maintained.
These tools, rather unfortunately referred to as cubes, vastly supported more than three dimensions. So it came as no surprise that around the change of the millennium, OLAP cubes were the be-all and end-all for organizations seeking to utilize their operational data in strategic decision-making.
But you should note that enriching data with new metrics and dimensions was tedious, frustrating, and time-consuming. Furthermore, the teams burdened with setting up and maintaining the data pipelines had to balance business requests and hardware constraints constantly.
With increasing computational capabilities, a specific type of relational database picked up steam: the column-oriented database management system.
Although these systems date as far back as the sixties, Sybase IQ was the first commercial version made widely available in the early nineties and acquired by SAP in 2010.
Columnar storage is at the heart of about every modern data warehouse software.
Columnar storage
A relational database provides data represented in a two-dimensional format: rows by columns.
This simplistic table below contains the following information about the named products:
- Product name
- Product packaging type
- Product volume
- Product price
| ID | Product name | Package type | Volume | Price in USD |
|---|---|---|---|---|
| 1 | Coca-Cola | can | 8oz | 4 |
| 2 | Fanta | can | 8oz | 4 |
| 3 | Budweiser | bottle | 12oz | 5 |
However, it’s essential to remember that this format only exists in theory: the storage hardware requires a serialized form.
Hard drives are organized through a series of blocks, each with the same fixed size. Therefore, grouping related data together minimizes the number of blocks that need to get read.
To improve the performance of seek operations:
- row-oriented databases group related rows.
- column-oriented databases group all values from a column.
To illustrate:
1:0001, 2:0002, 3:0003, . . .
Coca-Cola:0001, Fanta:0002, Budweiser:0003, . . .
can:0001,0002, bottle:0003, . . .
8oz:0001,0002, 12oz:0003, . . .
4:0001,0002, 5:0003
As seen from the last three columns (package type, volume, and price in USD), it is more than simply a row store with an index for each column. Instead, the primary key is the data itself, which maps back to a row ID.
Compared to row-based systems, this is the world turned upside down.
Keep in mind that for analysts, retrieving subsets of data is their sole concern. A columnar database has two substantial advantages that positively impact the speed of seeking operations to retrieve these subsets of data. These advantages are:
- Identical values within a column only need to be stored once, along with pointers to the rows matching it. This, in turn, reduces I/O when querying the data.
- Because the values of a column are of the same type, the data can be compressed efficiently, further reducing I/O.
Now you know what columnar storage is and why it’s at the heart of the enterprise data warehouse.
The following section will elaborate on the modern data warehouse.
Massively parallel processing (MPP)
Columnar storage drastically improved analytical operations' efficiency, but the emergence of cloud computing enabled big data analytics by scaling infinitely.
The paradigm responsible for infinite scaling is known as massively parallel processing (MPP).
It is a way of structuring hardware where storage is decoupled from computing and distributes processing power across several nodes (servers). In other words, rather than scaling vertically—adding more resources to the server—an MPP database scales horizontally, in a linear fashion, by distributing the workload to an increasing number of nodes.
These nodes all have dedicated resources that allow them to work independently from each other. However, a control node coordinates the workload so that all nodes work together efficiently.
The control node retrieves the input request, analyzes it, and distributes it across multiple compute nodes. In turn, the compute nodes run the query on different parts of the database in parallel and deliver the results back to the control node.
Evolution of MPP
Although MPP has been around for decades, it was extremely hard and expensive to set up and manage.
That changed when major cloud providers started offering MPP data warehouse capabilities as a service. Doing so reduced the complexity of setting up a modern enterprise data warehouse to a couple of clicks.
The initial setup cost with these data warehousing as a service (DWaaS) offerings is near zero, and charging is on a pay-for-usage basis.
Modern data warehouses, provided as a service, are now offered by dozens of vendors. The big three, AWS, Azure, and GCP, offer Redshift, Synapse, and BigQuery, respectively.
But there are some best-of-breed players, such as Snowflake, Firebolt, Yellowbrick, and Teradata. They all come with their strengths and features, supporting varying use cases.
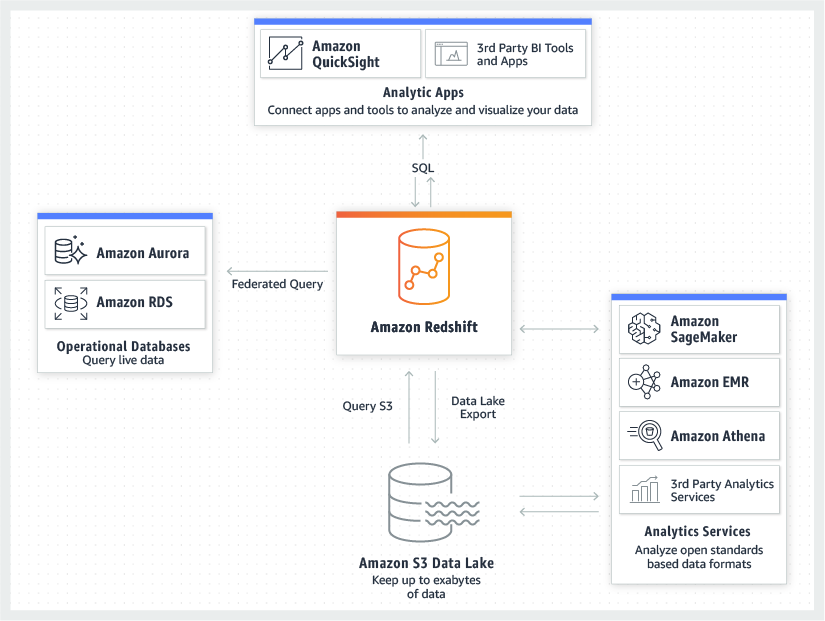
Amazon Redshift (source)
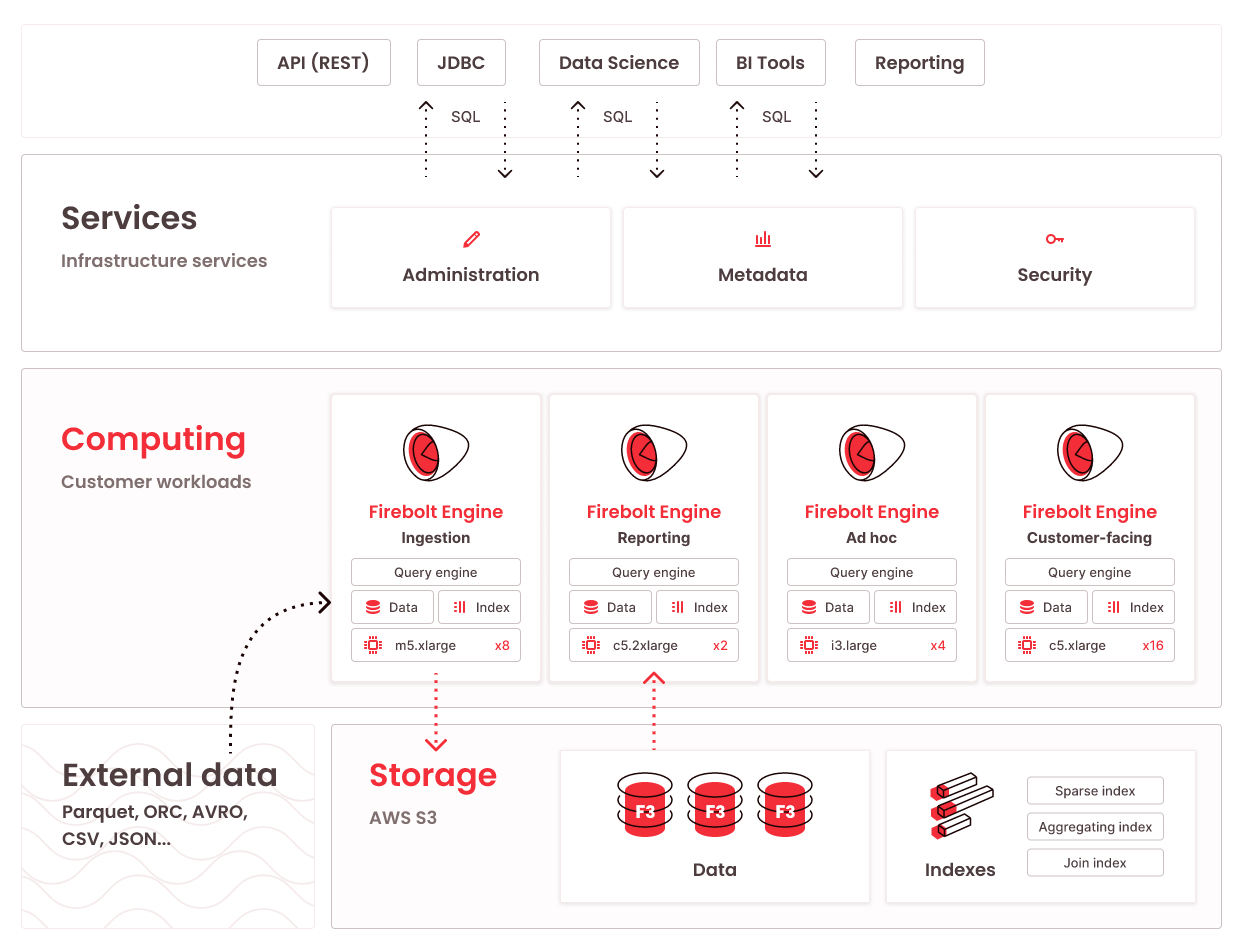
Firebolt (source)
Converging products
The vendors mentioned above continually invest in improvements and features for their cloud data warehouse offerings, bringing the data warehouse software category more in line with other database products.
I will demonstrate this with two examples:
1. Convergence toward the OLTP database
Some databases now support analytical and transactional workloads and get referred to with a specific label: NewSQL.
Software in this category supports real-time analytics on live transactional data without any chance of disruption. Despite support for various use cases that you typically associate with EDWs, they are often built from the ground up.
From a technological perspective, EDWs and NewSQL databases have very little in common. Some examples of products are PingCAP: TiDB and SAP HANA.
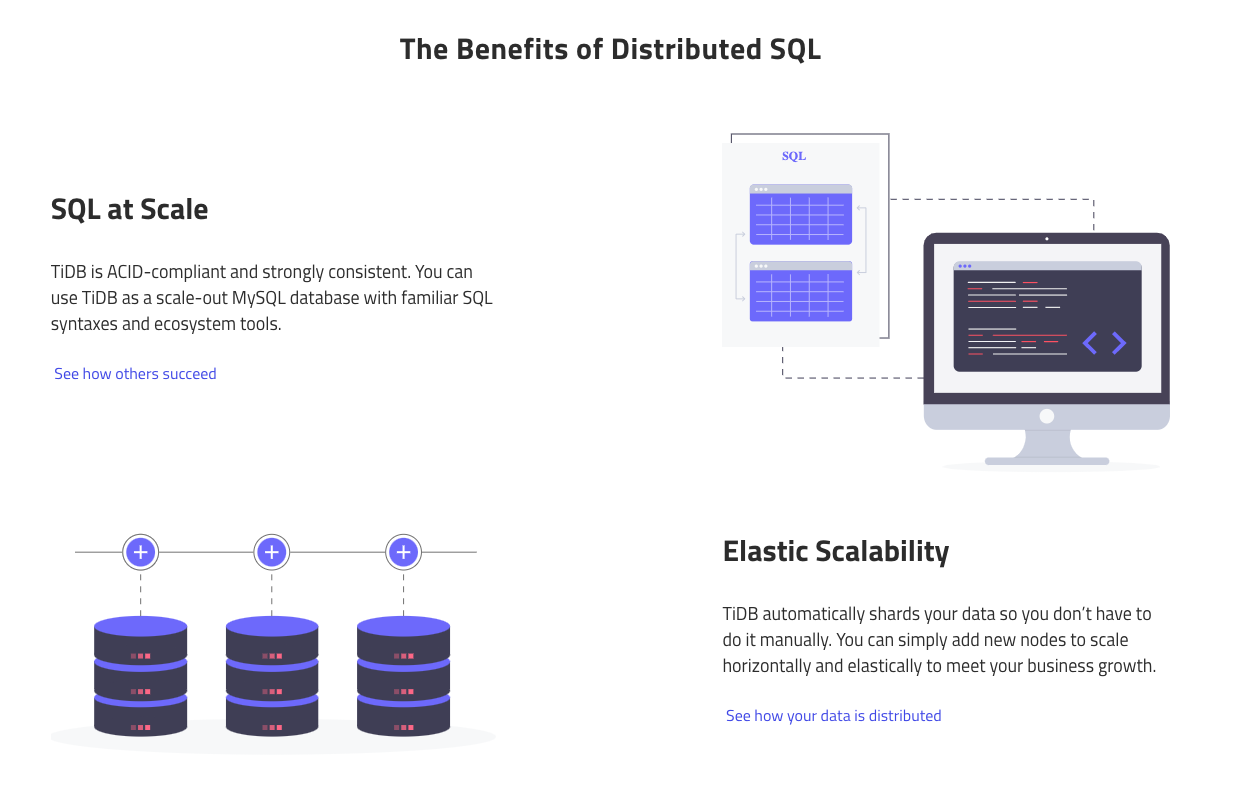
TiDB (source)
2. Convergence toward the data lake
On the other side of the spectrum, many vendors now support the storage and query of semistructured data.
There is also support for streaming ingestion (Snowflake’s Snowpipe, BigQuery’s streaming insert, and its machine learning capabilities—BigQuery ML) within the same SQL-based querying experience.
With ridiculously cheap storage decoupled from computing power, the data warehouse is closer to its cousin, the data lake(house).
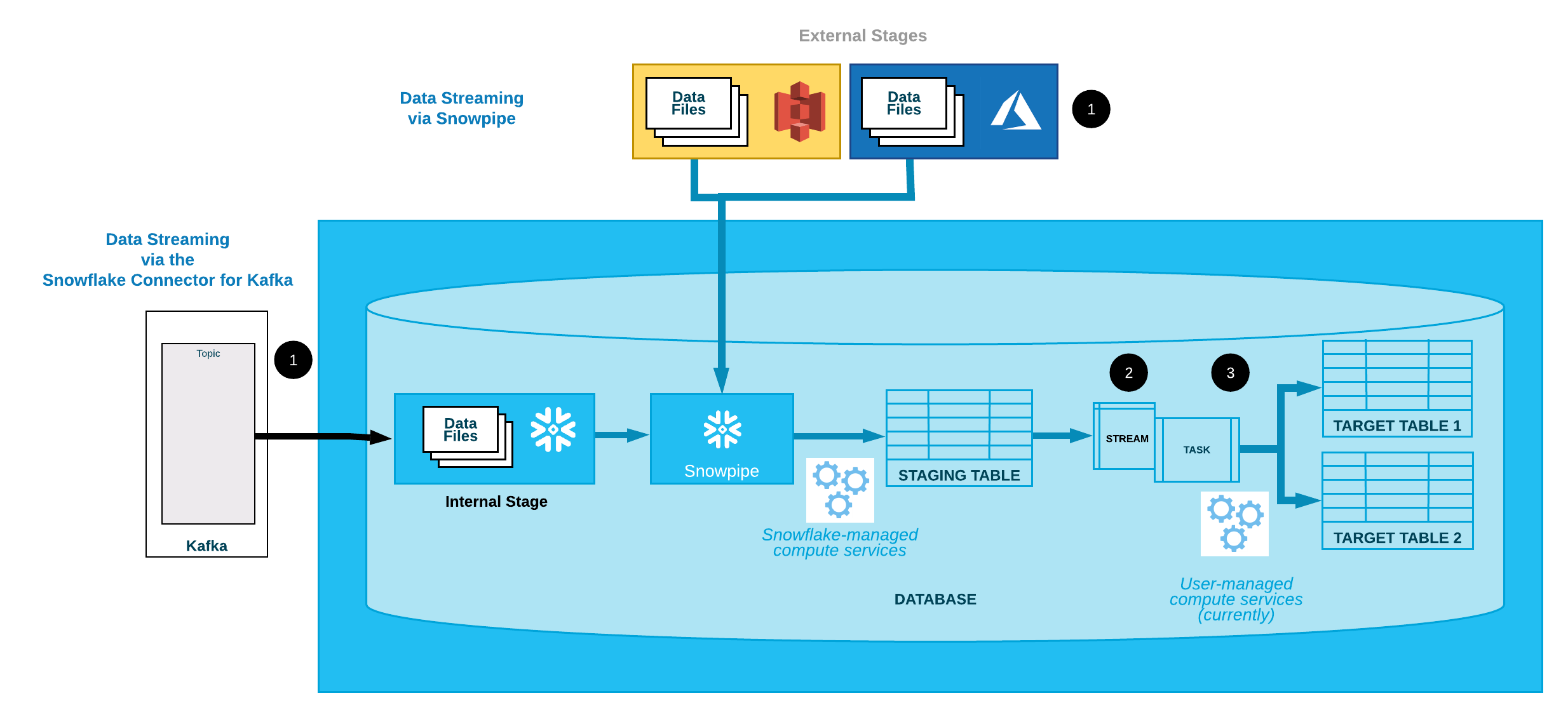
Snowflake's Snowpipe (source)
This final evolution often gets credited with changing the typical data pipeline workflow. For example, when storing data is exceptionally cheap, it doesn’t make sense to have an ETL (extract, transform, and load) workflow where data is stored in a data lake and transformed before loading it in a data warehouse.
In a modern data stack, both raw and structured data get stored in the same data warehouse.

Matillion ETL (source)
Tools such as dbt, Dataform, and Matillion offer a modeling layer on top of the data warehouse to enrich, clean, and structure the raw data into its final form within the same data warehouse. This process is known as ELT—extract, load, and transform.
Finally, a tool such as Panoply has a SQL-based modeling layer embedded in its data platform.
Conclusion
Any organization that wants to utilize its operational data for analytical purposes needs a column-oriented database, known as a data warehouse.
A modern data warehouse is a central piece in the modern data stack: it runs in the cloud, scales infinitely, and supports an ELT workflow.
If you’re looking for a comprehensive solution for data organization and data synchronization with your warehouses, check out Panoply.



