One of the most critical steps in building a data warehouse or building a data lake is integrating your data sources into one format.
Data integration is a crucial step, and it can be done using Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) processes. While ETL was the traditional method, ELT has emerged as a more efficient process with the rise of cloud technologies. Here's a closer look at the architecture of ETL and ELT pipelines to help you make an informed decision. The core difference between the processes is when and where data transformations take place.
So, which one should you use for your business? ELT or ETL?
In a previous post, I discussed ETL vs. ELT from a broader perspective, along with the advantages and disadvantages of each process. In this post, I'll go into the details of the architecture of ETL and ELT data pipelines.
To help choose the best approach, I'll discuss the things you should consider in your ELT design, best practices to follow, and challenges to overcome in the process.
ETL Architecture
To start, let's explore how data flows through an ETL pipeline. The following figure illustrates the key steps in ETL data flow:
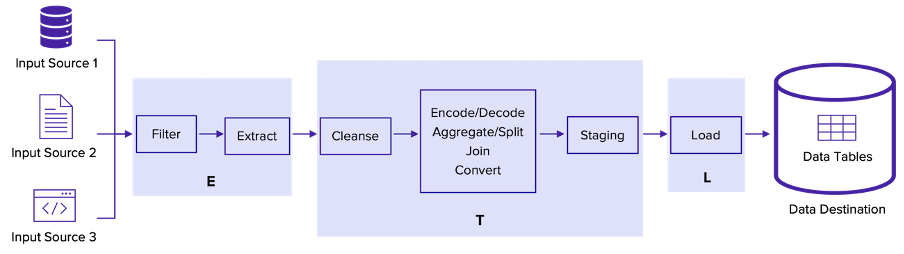
Extract
Imagine you have a CSV file containing employee data and two relational databases with product data from two suppliers. You're intending to collect this data, map it to your format, and store it in your database or data warehouse.
In the first step, you'll gather these data sources and collect data using an extracting tool.
Your input data can come in different formats from a variety of sources such as:
- SQL and NoSQL databases
- CSV, JSON, and XML files
- log and monitoring files
- REST APIs
- Output files from web scraping
However, some of your data sources can be updated after your initial data extraction.
While some sources may notify you when such changes occur, others may be unable to identify modifications to data. In this situation, you may have to extract data fully or partially to reflect the changes in your sources.
Furthermore, you might not need all the attributes in your supplier's product database. You may have to carefully plan and filter the data elements to extract from the sources.
Transform
Undoubtedly, transforming is the most crucial step in the ETL process. This is where your input data is cleansed, mapped, and transformed to match the schema in your data warehouse.
First, you'll cleanse the data by removing duplicates, finding missing values, and sorting out ambiguities in data.
Then, you'll perform transformations to map the data to your own format.
One of the common transformations you may come across is encoding and decoding values. For instance, your input data may have "Y" and "N" encodings, whereas you may have stored them as "Yes" and "No."
Similarly, you may need to convert attributes such as gender, dates, and currency data to make sure they are in the same format, as well.
Another common transformation is aggregating and splitting values. You may calculate a total value to aggregate some attributes or split an address into multiple fields to store them easily.
Furthermore, you may join data from different sources to create combinations that are meaningful for your business.
Once all the transformations are done, you'll move the data to a temporary staging area so that you can easily roll back in case of any issues.
Load
In the final step, you'll load the staged data into the target data tables in the data warehouse. However, it can get more complicated in practical scenarios.
For instance, your supplier data can be frequently updated because of changes in product types and quantities.
In such scenarios, you may have to decide if your data ETL process should load all data each time or load only the modified data. These approaches are known as full and incremental load, respectively.
In addition, you may have to decide on the volume of data to load during each ETL process run. You can either load your data in batches or as streams if your data updates in real time.
Challenges in ETL
As you may have realized, designing the ETL process can quickly become rather complex. Here are some of the challenges you may come across when laying out an ETL pipeline:
- Performance: More often than not, the transformation step can cause delays in the ETL process because of the many data conversions applied to input data. This delay increases when your input comes from diverse sources, introducing different transformations for each of them.
- Scalability: In the long run, your business may require new input sources or increases in the amount of input data. Such instances will require you to perform the cumbersome task of modifying your ETL design and re-implementing the pipeline.
- Maintenance: Because of the complex nature of the pipeline, setting up a maintenance framework can be difficult. Data transformations and adding and removing input sources can introduce anomalies and mismatches in your data. The ETL design should incorporate a monitoring tool to identify and troubleshoot such errors, especially in the transform stage.
- Ensuring data quality and integrity: As the ETL pipeline processes data from many sources, the quality of data depends on the reliability of the ETL process. Therefore, the pipeline should have quality assurance tools to ensure that it's on the right track.
ELT Architecture
Because cloud data warehouse use is increasing and unstructured data is being used more often for analyses, the ETL process is shifting to manage large amounts of data.
In ELT, the transformation step happens after loading all input data to the data destination.
Your data destination can be a cloud data warehouse or a data lake. These storage options come with highly scalable processing power that allows loading and transforming large amounts of data.
ELT pipeline
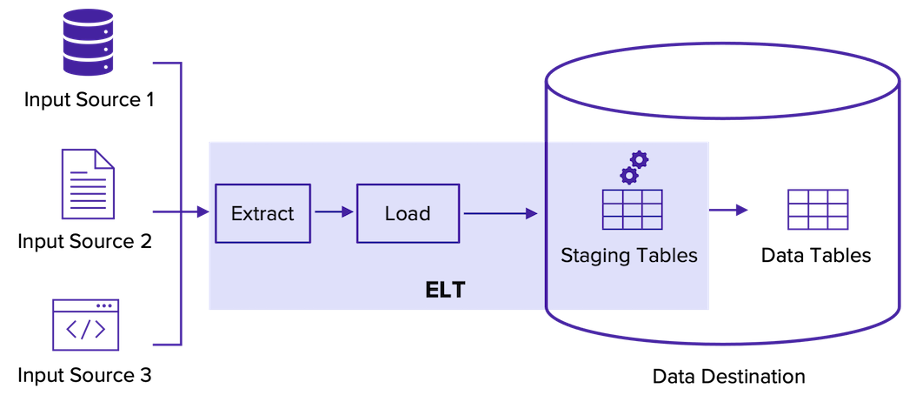
As the image above shows, the ELT pipeline is more straightforward than the ETL process.
You'll first extract and load your input data to the staging data tables in your data destination. After performing data transformations, usually in SQL, the data will be moved to the final data tables and stored for future use.
Best Practices to Follow With ELT
If you're using a cloud data warehouse and integrating data using ELT, you may still need to plan your data pipeline.
Here's a list of best practices to follow in this process. Keeping in line with these will go a long way in building reliable and effective data pipelines.
- Identify your data sources: Recognize if they are dependent on each other. Data sources that don't have dependencies can process in parallel to save resources, while dependent ones should process serially.
- Determine your data destination: Identify if your storage is a database, data warehouse, or data lake and if you have one or more storage locations to connect via ELT.
- Specify the data you'll extract: This includes the data tables, columns, or files you would extract and store from each input source.
- Plan your data validation process: Figure out the data cleansing and preprocessing steps you'll need.
- Identify the transformations: Plan the transformation steps you'll need for each input source.
- Determine the frequency of your ELT runs: Identify if you'll have full or incremental data loads and batch or stream processing.
- Pick your ELT tool: Determine if you'll build your own or use an already available ELT tool.
- Identify the business intelligence (BI) tools you'll need: There are a lot of awesome BI tools that will help you to obtain insightful analytics from your data.
- Plan the maintenance process: Determine how you'll maintain and monitor your ELT pipeline to ensure its reliability.
ELT or ETL: What is the best choice for you?
At the end of the day, choosing between ELT and ETL can depend on the requirements of your business, the current system you have, and your future plans.
Whether you decide to use ELT or ETL, planning and implementing your own data pipeline can be complicated and inefficient.
If you're looking for a cloud data platform that will enable you to connect your input sources and start syncing your data within minutes, Panoply is for you.
Panoply offers automated integrations to a number of data sources and BI tools to get some insights into your data.
You can explore the Panoply platform with a 21-day free trial and see how your data requirements will fit in.



