On a high-level, ETL transforms your data before loading, while ELT transforms data only after loading to your warehouse.
In this post, we'll look in detail at the differences between how ETL and ELT work to help you identify which process is the most suitable for the data operation you have at hand.
If you're more interested in the differences in design and architecture, check out our other blog post here.
ETL (extract, transform, load) has been around for decades and has been the go-to approach for gathering and reforming data into one format. However, with cloud data warehouses coming into the picture, ELT (extract, load, transform) has emerged as the newer approach for combining data.
It's important to realize that both ETL and ELT serve the same purpose but differ in their implementation.
Whether you're using ETL or ELT, you'll perform three key steps.
- Extract: In this step (always the first), you will pull data from all your data sources. This extraction can be either from structured relational databases or unstructured data sources such as images and emails.
- Transform: In this step, you clean, process, and convert data, fitting it into the existing format in your data storage.
- Load: This is the step where you load data into the storage destination and analyze them using an appropriate business intelligence tool.
So, which approach is better for you? The answer lies in the details of the processes.
What is ETL?
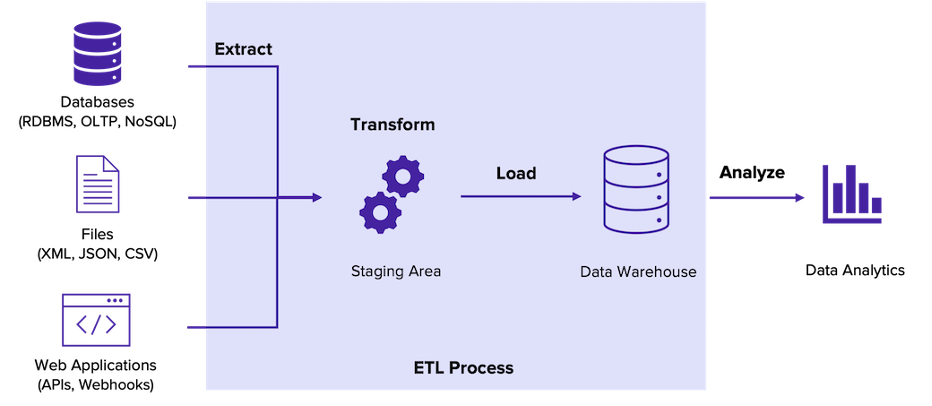
Image source: Malsha Ranawaka
Originally, the ETL process was coded by hand to collect data from relational databases. Nowadays, professionally developed ETL tools usually carry out this process automatically, as they can extract data from a number of sources and automate the operations.
The Extraction Process
As illustrated in the above figure, an ETL tool will extract data from your data sources. You can have various data sources ranging from databases and flat files to REST APIs that release application data.
The Transformation Process
Data transformation occurs in the staging area once the ETL tool has extracted the data. It's necessary to have a staging area since data sources may release data at different times.
For instance, a sales database will have data updated daily, while an employee database may only have data released every month.
The Loading Process
In the final loading step, the ETL tool will store the transformed data in your data warehouse.
The Advantages of ETL
- Manage data warehouse storage: Is your data storage a cost-sensitive system? In that case, using ETL may help you keep the storage costs low. ETL tools will transform and filter to keep only the data you need. This will reduce the use of data storage.
- Compliance with security protocols: You may be keeping in line with data privacy regulations such as GDPR, SOC2, and HIPAA or requirements that are specific to your company. Such regulations often require you to remove, mask, or encrypt sensitive data like email or IP addresses before storing them in your data warehouse. You can easily accomplish this within the ETL process by hiding or removing data at the transform stage.
The Disadvantages of ETL
- Low flexibility: Do you have input data sources and formats that can change frequently? If you're using ETL, you'll need to configure the transformations for such format changes and edge cases in advance. Otherwise, you'll need to stop and modify the ETL process for every edge case. This can result in a considerable maintenance cost.
- Slow: You may need to wait until all the transformations are complete to load the data into the warehouse.
- Continuous maintenance: As mentioned previously, you may need to continuously maintain the ETL process to ensure it's up to date with your changing input sources.
- High initial cost: The initial cost in setting up your ETL process can be high, as you may need to define the processes and transformations you'll need for your project.
What is ELT?
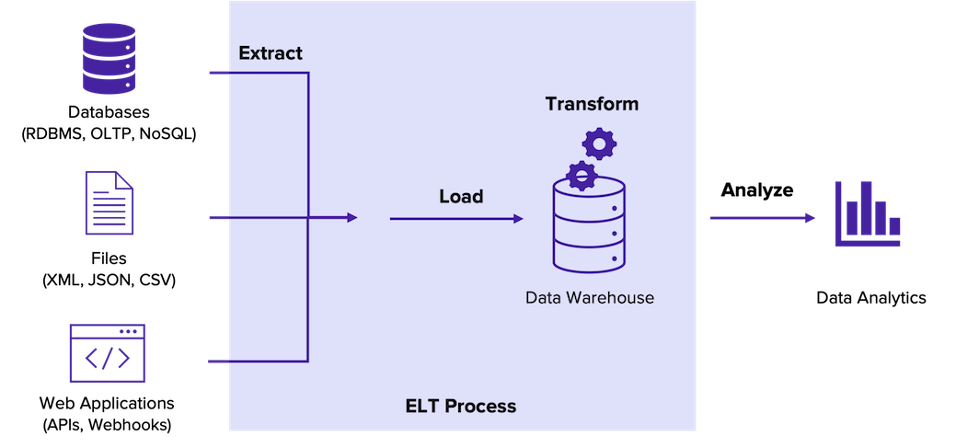
Image source: Malsha Ranawaka
The switch from ETL to ELT came about with 2 significant transitions:
- the increased use of unstructured data
- and the recent popularity (and reduced cost) of cloud-based storage systems.
Transforming unstructured data such as images, audio, and video can take a significant amount of time. This can slow down the ETL process. Therefore, data is first stored in storage systems so that transformations can occur as needed.
The shift to ELT is largely backed by cloud storage technologies such as data warehouses and data lakes. These storage systems support storing unstructured data and performing fast and large-scale data transformations.
The Advantages of ELT
- Fast: In the ELT process, there's no waiting involved. The best ELT tools will instantly load data into your data warehouse where they're ready for transformation.
- Flexible: Given that transformations don't need to be defined at the beginning, you can easily integrate new and different data sources into the ELT process.
- Low initial cost: ELT tools can easily automate the process of onboarding data. As you don't need to define transformations, the initial cost is lower in comparison to ETL.
- Minimal maintenance: In contrast with ETL, you'll have less maintenance on your plate as the process is simpler and more automated. Since transforming is the last step in the process, it's easier to fix bugs in your transformation pipeline. Unlike in ETL, you can re-run only the updated transformation to get the correct output.
- High scalability: If the amount of data you use increases, you can quickly expand your storage in the cloud. ELT processes can easily adapt to such instances and manage data ingestion at large scales, while ETL processes may need to be redefined.
The Disadvantages of ELT
- Data security risks: Data security can be a concern when loading large amounts of raw data into your storage. To minimize security risks, you'll need to manage user and application access of raw data stored in your data warehouse.
- Low compliance with data security protocols: Since data is stored with minimal processing, you may need to take additional steps to ensure compliance with data security protocols. Many data warehouses, such as Panoply, have built-in security protocols including GDPR, HIPAA, and SOC2 to support data compliance.
ETL vs ELT comparison summary
We've summarized the key differences between ETL and ELT in the table below for a quick glance.
| ETL | ELT | |
| Source Data | Support storing structured data from input sources | Can be used for structured, unstructured, and semi-structured data types |
| Data Size | Best suited for smaller amounts of data | Can be used for large amounts of data |
| Storage Type | Can be used for on-premises or cloud storage | Optimized for cloud data warehouses |
| Latency | High, as transformations need to be completed before storing data | Low, as minimal processing is done before storing in the data warehouse |
| Flexibility | Low, as data sources and transformations need to be defined at the beginning of the process | High, as transformation need not be defined when integrating new sources |
| Scalability | Can be low, as the ETL tool should support scaling of operations | High, as ELT tools can be easily configured for changing data sources |
| Maintenance | May need continuous maintenance in case of changes in data sources or formats | Low maintenance required as usually ELT tools automate the process |
| Compliance with Security Protocols | Easy to Implement | May need to be supported by data warehouse/ELT tool |
| Storage Requirement | Low as only transformed data is stored | Can be high as raw data is stored |
When should you use ELT instead of ETL?
Now that you know the differences between ETL and ELT, you may be wondering which is the best option for you.
Here are some practical use cases where using ELT would give you a better outcome:
- When you have heaps of data to process: If your project has large amounts of data that need to be loaded and analyzed, you'll benefit from using ELT. In contrast to ETL, collecting your data in one place will take less time with ELT. After loading, ELT will use the fast processing power in cloud storage to perform your data transformations.
- When you need to store data fast: An ELT tool can gather all your raw data in less time compared to using ETL.
- When you need raw historical data for future analysis: If your business will benefit from analyzing trends in data, you may need to keep raw historical data at hand. Since ELT stores all your raw data in the data warehouse, you won't have to reload the data during analysis.
- When you need a flexible data integration process: If your company has data sources and formats that change frequently, ELT will create a flexible process to cater to these requirements.
Conclusion
Both ETL and ELT will serve your data integration purpose in different ways. Choosing the solution that's best for you can depend on various factors, such as:
- the data you have
- the type of storage you use
- and the long-term needs of your business
At the end of the day, if you decide to go for an ELT solution, Panoply's cloud data platform will help you simplify the process.
The platform combines the ELT process and the data warehouse and provides you with automated integrations.
Getting started is easy—explore Panoply for yourself in our free trial and see how you can set up effortless data integrations in minutes.



