When we say “big data”, many think of the Hadoop technology stack. Is this the big data stack?
Well, not anymore. Big data concepts are changing. The data community has diversified, with big data initiatives based on other technologies:
- NoSQL databases like MongoDB, PostgreSQL and Cassandra running huge volumes of data.
- Cloud-based data warehouses which can hold petabyte-scale data with blazing fast performance.
- Even traditional databases store big data—for example, Facebook uses a sharded MySQL architecture to store over 10 petabytes of data.
The common denominator of these technologies: they are lightweight and easier to use than Hadoop with HDFS, Hive, Zookeeper, etc. Some are offered as a managed service, letting you get started in minutes.
Towards a Generalized Big Data Technology Stack
We propose a broader view on big data architecture, not centered around a specific technology. How do organizations today build an infrastructure to support storing, ingesting, processing and analyzing huge quantities of data? This is the stack:
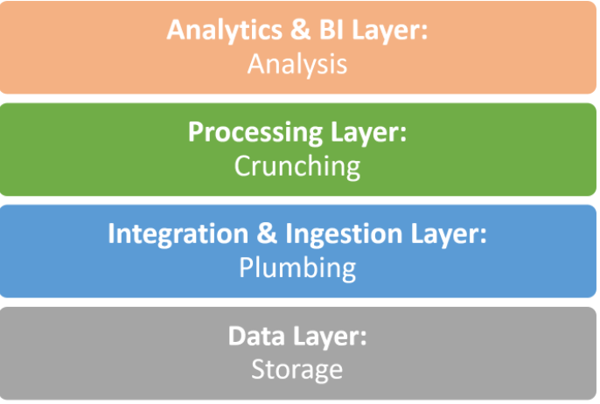
The Data Layer
At the bottom of the stack are technologies that store masses of raw data, which comes from traditional sources like OLTP databases, and newer, less structured sources like log files, sensors, web analytics, document and media archives.
Increasingly, storage happens in the cloud or on virtualized local resources. Organizations are moving away from legacy storage, towards commoditized hardware, and more recently to managed services like Amazon S3.
Data Storage Systems
A few examples:
- Hadoop HDFS—the classic big data file system. It became popular due to its robustness and limitless scale on commodity hardware. However, it requires a specialized skillset and complex integration of a myriad open source components.
- Amazon S3—create buckets and load data using a variety of integrations, with 99.999999999% guaranteed durability. S3 is simple, secure, and provides a quick and cheap solution for storing limitless amounts of big data.
- MongoDB—a mature open source document-based database, built to handle data at scale with proven performance. However, some have criticized its use as a first-class data storage system, due to its limited analytical capabilities and no support for transactional data.
The Data Ingestion & Integration Layer
To create a big data store, you’ll need to import data from its original sources into the data layer. In many cases, to enable analysis, you’ll need to ingest data into specialized tools, such as data warehouses. This won’t happen without a data pipeline. You can leverage a rich ecosystem of big data integration tools, including powerful open source integration tools, to pull data from sources, transform it, and load it to a target system of your choice.
Big Data Ingestion Tools
A few examples:
- Stitch—a lightweight ETL (Extract, Transform, Load) tool which pulls data from multiple pre-integrated data sources, transforms and cleans it as necessary. Stitch is easy to setup, seamless and integrates with dozens of data sources. However, it does not support data transformations.
- Blendo—a cloud data integration tool that lets you connect data sources with a few clicks, and pipe them to Amazon Redshift, PostgreSQL, or MS SQL Server. Blendo provides schemas and optimization for email marketing, eCommerce and other big data use cases.
- Apache Kafka—an open source streaming messaging bus that can creates a feed from your data sources, partitions the data, and streams it to a passive listener. Apache Kafka is a mature and powerful solution used in production at huge scale. However it is complex to implement, and uses a messaging paradigm most data engineers are not familiar with.
The Data Processing Layer
Thanks to the plumbing, data arrives at its destination. You now need a technology that can crunch the numbers to facilitate analysis. Analysts and data scientists want to run SQL queries against your big data, some of which will require enormous computing power to execute. The data processing layer should optimize the data to facilitate more efficient analysis, and provide a compute engine to run the queries.
Data warehouse tools are optimal for processing data at scale, while a data lake is more appropriate for storage, requiring other technologies to assist when data needs to be processed and analyzed.
Data Processing Tools
A few examples:
- Apache Spark—like the old Map/Reduce but over 100X faster. Runs parallelized queries on unstructured, distributed data in Hadoop, Mesos, Kubernetes and elsewhere. Spark also provides a SQL interface, but is not natively a SQL engine.
- PostgreSQL—many organizations pipe their data to good old Postgres to facilitate queries. PostgreSQL can be scaled by sharding or partitioning and is very reliable.
- SQream—fully relational SQL database with automatic tuning, ultra fast performance, compression and scalability. (Disclaimer, they're also our parent company.)
- Amazon Redshift—darling of the data industry, a cloud-based data warehouse offering blazing query speeds that can be used as a relational database.
Analytics & BI Layer
You’ve bought the groceries, whipped up a cake and baked it—now you get to eat it! The data layer collected the raw materials for your analysis, the integration layer mixed them all together, the data processing layer optimized, organized the data and executed the queries. The analytics & BI is the real thing—using the data to enable data-driven decisions.
Using the technology in this layer, you can run queries to answer questions the business is asking, slice and dice the data, build dashboards and create beautiful visualizations, using one of many advanced BI tools. Your objective? Answer business questions and provide actionable data which can help the business.
BI / Analytics Tools
A few examples:
- Tableau—powerful BI and data visualization tool, which connects to your data and allows you to drill down, perform complex analysis, and build charts and dashboards.
- Chartio—cloud BI service allowing you to connect data sources, explore data, build SQL queries and transform the data as needed, and create live auto-refreshing dashboards.
- Looker—cloud-based BI platform that lets you query and analyze large data sets via SQL—define metrics once set up visualizations that tell a story with your data.
The Entire Stack in One Tool?
Should you pick and choose components and build the big data stack yourself, or take an integrated solution off the shelf? Until recently, to get the entire data stack you’d have to invest in complex, expensive on-premise infrastructure. Today a new class of tools is emerging, which offers large parts of the data stack, pre-integrated and available instantly on the cloud.
Another major change is that the data layer is no longer a complex mess of databases, flat files, data lakes and data warehouses, which require intricate integration to work together. Cloud-based data integration tools help you pull data at the click of a button to a unified, cloud-based data store such as Amazon S3. From there data can easily be ingested into cloud-based data warehouses, or even analyzed directly by advanced BI tools.
Panoply's cloud data platform covers all three layers at the bottom of the stack:
Data—Panoply's cloud based storage can hold petabyte-scale data at low cost.
Integration/Ingestion—Syncing data takes just a few minutes thanks to Panoply's intuitive UI.
Data Processing—Panoply lets you perform on-the-fly queries on the data to transform it to the desired format, while keeping the original data intact. It connects to all popular BI tools, which you can use to perform business queries and visualize results.
Most importantly, Panoply does all this without requiring data engineering resources, as it's fully integrated, right out of the box.
Big Data—Beyond Hadoop
For a long time, big data has been practiced in many technical arenas, beyond the Hadoop ecosystem. Big data is in data warehouses, NoSQL databases, even relational databases, scaled to petabyte size via sharding. Our simple four-layer model can help you make sense of all these different architectures—this is what they all have in common:
- A data layer which stores raw data.
- An integration/ingestion layer responsible for the plumbing and data prep and cleaning.
- A data processing layer which crunches, organizes and manipulates the data
- An analytics/BI layer which lets you do the final business analysis, derive insights and visualize them.
By infusing this framework with modern cloud-based data infrastructure, organizations can move more quickly from raw data to analysis and insights. Data engineers can leverage the cloud to whip up data pipelines at a tiny fraction of the time and cost of traditional infrastructure.
As an analyst or data scientist, you can use these new tools to take raw data and move it through the pipeline yourself, all the way to your BI tool—without relying on data engineering expertise at all.



