Let's talk about data. The sheer volume of the data collected today is enormous. When I try to even imagine the amounts...it's staggering.
And the amount is growing day by day, as is the analytics involved. I find it’s tough to cope with the loading. Then, making it available to different reporting engines for end users to access it. I am sure you must be getting complaints related to performance and the time it takes to load. And if you, like me, need to work on a data warehouse solution that's effective and viable, you need to be constantly aware of what a critical component your work is to an analytics strategy.
This article will walk you through the day-to-day challenges a developer faces with data warehouse development. We’ll explore designing tables, selecting right data types, and how to resolve issues related to data types and data loading. I will also highlight the best tools and methods to use for data integration and automation from multiple sources.
Available Redshift data types
Unlike other RDBMS, Redshift is used solely for data warehousing. You will not see many of the data types like LOBs or LONG in Redshift. We don’t need them in a data warehouse for which numbers play the most significant role. We can design a table for data warehousing using data types like SMALLINT, INTEGER, and BIGINT to store whole numbers of various ranges. And, use DECIMAL or NUMERIC to store values with user-defined precision. Similarly, we use VARCHAR, DATE, TIMESTAMP for its respective data. The table below illustrates different data types and the usage for each.
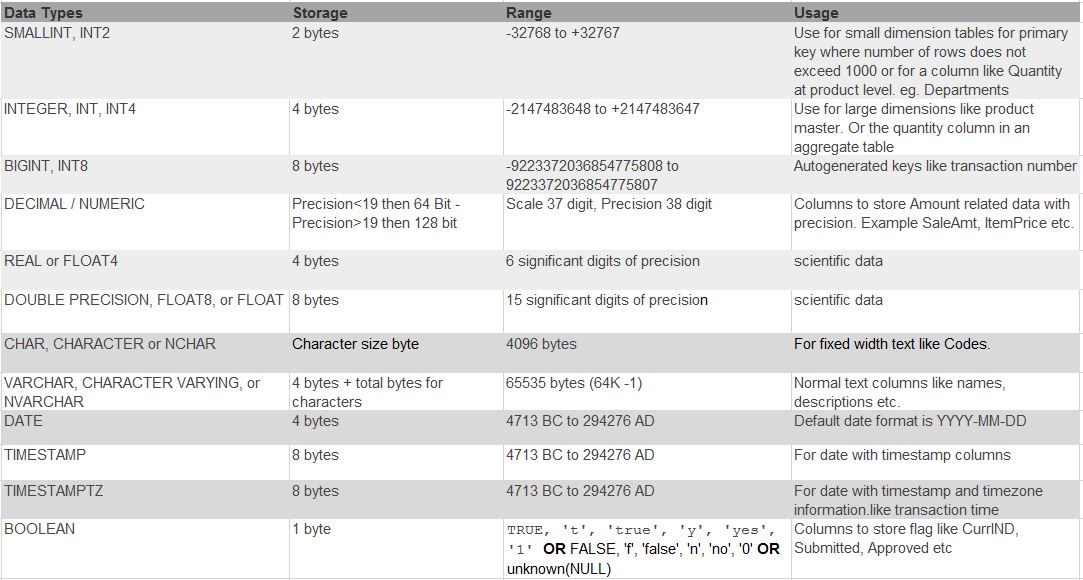
Working with numbers
It’s all a numbers game. You don’t want to lose data integrity due to wrong data type selection. Redshift provides standard number data types for different uses, which include integers, decimals, and floating-point numbers. We need to be careful about how the conversion and compatibility of number data type works while manipulating or querying data.
Designing a table using the number data type
Selecting the right data types can help ensure that the data we are storing keeps the database as small as possible. I do this by selecting only the data types the table needs, rather than choosing data types at random. Careful selection of data type reduces the size of the rows, and by extension, the database, making reads and writes faster and more efficient. An example of optimally designing a table and selecting the best data types with correct encoding is presented below.
Compatibility and conversion issues
Do not select data types nor design the ETL in a hurry as it can cause errors, or worse, data corruption. Knowing how each data type behaves and the events that occur when the checks are performed will be of help when working on table design. Compatibility checks and conversion occur during various database operations, including:
- Data manipulation language (DML) operations on tables
- UNION, INTERSECT, and EXCEPT queries
- CASE expressions
- Evaluation of predicates, such as LIKE and IN
- Evaluation of SQL functions that do comparisons or extractions of data
- Comparisons with mathematical operators
Bad table design using incorrect data types
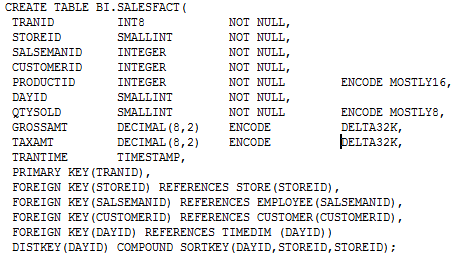
Beware of defining wrong data type in columns; for example, a column with datatype as INTEGER when the data is a decimal. Using random data types and data length is considered bad table design; for example, considering the SALESFACT table STOREID and DAYID columns will have limited distinct values because they reference a dimension that has several hundred to few thousands rows only. Using a data type like INT8 or even INT4 will result in more storage utilization than it actually needs; so SMALLINT is the most suitable data type for these columns. Data type for columns that store time keys where as expected data is max 10-digit only.
ETL code not handling conversions
You did everything right, and there still seems to be a mismatch in data between data file and table. Why? Likely because you mishandled conversions. A simple example of where things could go wrong is with decimal values getting lost while data is loaded into an intermediate table. We need to be careful in every stage, from loading data from S3 to temporary table to transformed data from temporary table to target table. ETL needs to handle conversion explicitly in these cases. Data corruption can occur if the temporary tables are not created with correct data types as per the target tables because implicit conversion during COPY can result in loss of decimal information if the table is not designed using correct precision.
Use case: Insert/update fails due to compatibility issue
Let’s look at an example of a compatibility issue that is caused either due to bad ETL or bad table design.
Here is a simple table having DAYID with unfit data type for holding data related to time dimension.

I am inserting a row in this table by mimicking an integer value as text to produce the error condition. Implicit conversion will not happen because the source and target data type do not match in this case.
Example 1:

Example 2: Here is an example of inserting an out-of-range value and getting an error.

Use Case: Insert/update corrupts the data due to conversion issue
You will need to analyze the source data properly before designing the data loading procedures to avoid data corruption issues as they are resultant of the wrong unnoticed implicit conversions. Below are 4 rows of data to be ingested with decimal values.
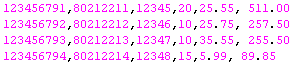
An intermediate table is first loaded using the Redshift COPY command. This table has incorrect usage of data type for columns UNITPRICE and TOTALAMT.

After I load data into the intermediate table, data is then loaded into a target fact table.

It has resulted in a corruption of data due to implicit conversion and wrong data type usage.
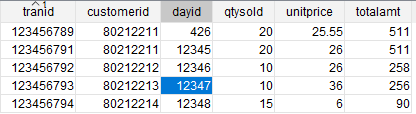
Designing the table and ETL
Things we need to consider while designing tables and ETL:
- Make sure you understand the data properly. I first work on a layout of the file that has list of columns and the incoming data types. This can prove very helpful in designing tables that suit the data well.
- Use local temporary tables for staging the data in Redshift prior to loading in the target table. This will help in case there is a possibility of character data coming as part of the integer column. Cleanup of these rows can be performed prior to loading in the target table.
- Choose the data type that best fits the data in order to save on storage and in turn get better performance as the server will need to perform less amount of IO.
- Use CAST and CONVERT functions in ETL code wherever there is a possibility of implicit/explicit conversion to protect the data from getting corrupted.
- Choose the right compression encoding for columns to save on storage. Do not compress columns that are part of SORTKEY.
Redshift: No stored procedures
As a database developer, you will likely miss this feature in Redshift. Life was easy with PL/SQL, wasn't it? We develop and deploy the code on the server side, but with Redshift we have to keep code as SQL scripts out of the database. For sure, we’ll also miss some of the capabilities, like packages for related code, and the ability to iterate and process data using FOR LOOP. UDFs are helpful, but can only perform calculations, which do not even support SQL.
On the other hand, there are integration tools that make our life easier by providing the ability to drag and drop columns and map source to target data entities. ETL can be designed using tools like Talend DI, Oracle Data Integrator (ODI), or custom Python script to execute the ETL steps in sequence. ETL needs to be designed carefully, keeping in mind the data source and target data types. Properly designing the database tables and ETL are both key to successful data warehousing.
As you plan your database, there are table design decisions that will heavily influence overall query performance. Table design choices also significantly impact storage requirements, which in turn affect query performance by reducing the number of I/O operations and minimizing the memory required to process queries. Therefore, when you design a table, choose data type wisely.
Analyze the table for compression benefits
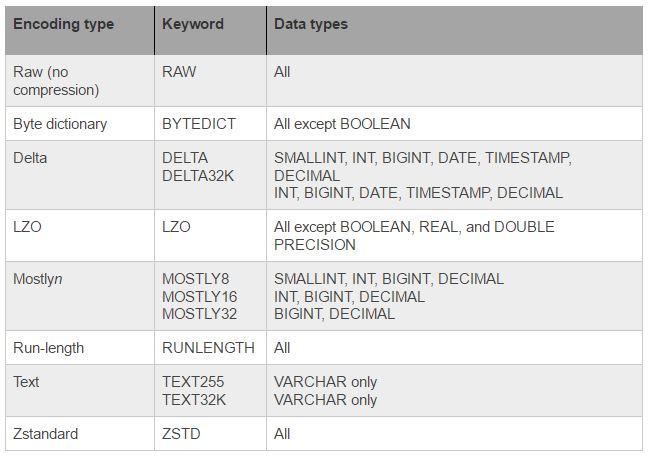
I like this feature of Redshift a lot. Compression is a column-level operation that reduces the size of data when it is stored and conserves storage space. It reduces the size of data that is read from storage, which reduces the amount of disk I/O and therefore improves query performance. So, choosing the right encoding for column data type is very important.
I would mostly rely on encodings given in the table below.
It’s effortless! I would use Redshift’s analyze compression to find the best suitable compression for columns rather than doing it manually. To do this, run ANALYZE COMPRESSION command on a loaded table created without any compression.
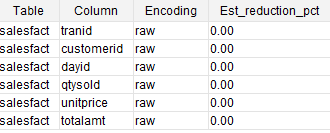
You need to look at the Est_redution_pct column for a suggestion on best compression encoding for a column. The column shows the percent of compression that can be achieved using a particular encoding. You would not want to compress SORTKEY columns and add overhead of uncompressing the data before filtering. That’s bad for performance.
You can also run the COPY command with the COMPUPDATE flag turned on (defaults with every COPY command) and the COPY command will automatically compress the columns based on the optimal compression type (only if the table is empty).
Use case: Solving the compatibility issue
Using the above Example 1, make sure the source and target have the same data types. When inserting INT data type from the source, the target column should also be INT. Or you will need to use CONVERT or CAST function to convert the value to match target data type.
In the Example 2, SMALLINT is not a suitable data type. We need to use data type that can handle a bigger range of data. I will use INT4 to handle this length of data. Because SMALLINT can have a maximum value between -32768 to +32767 a value like 99999 would not be accepted.
Use case: Solving the data corruption issue
Data corruption is an end-to-end design issue. You need to make sure the interface table matches with the source data as well as the target table. In the example, the intermediate table was consuming the precision because of the bad table/column design. To solve this, create the intermediate table by making a copy of the target table. We also need to make sure while performing calculations proper explicit conversion is done if different data types are used.
Handling of views before/after changing data types
You probably have worked on other RDBMS and think that views will work similarly in Redshift, but they don’t. We need to be very careful when making changes to any table because views dependent on the table may not be useful or the DDL of a view will not be compatible with the table.
I will use the given workaround to solve this issue. The easiest way to change the column data type is to add a new column with proper data type, copy the data between the two columns, drop the old column, and rename the new column to the proper name. But remember that this view will not allow dropping of a column. In order to switch data types for a column that a view is dependent on, you will need to first drop the view before running the data type change sequence. So, a backup of view is a must prior to dropping the view.
The complete sequence is described below:

Final thoughts
To leverage the capabilities of Redshift or any database for analytical or BI systems, it is important that we design databases properly. Knowing what can impact the overall performance of a data warehouse system is critical. But it may not be sufficient as data comes from multiple sources and maintaining the scripts can result in usability, security, and integration issues.
It’s a complex task, for sure. But employing a tool such as Panoply relieves some of the pressure from the developer. Panoply offers a collection of predefined data source integrations to popular databases and apps, making it easy to both connect your data and spin up a data warehouse, all without complicated code.
To learn more, schedule a personalized demo today!



