Google Cloud Platform has long been the cloud provider of choice for web analytics, with the impressive BigQuery being Google's massively parallel processing (MPP) option. (You've probably heard about MPP if you're on Hadoop.)
BigQuery is very friendly to its users (let's agree that BigQuery is as pleasant as its SQL knowledge), which fosters new users. In part, thanks to a more detailed exploration of Google Analytics data, for example.
This article aims to present BigQuery and its existing data types per SQL categories. I'll also give one practical use case where knowing these data types can be helpful: data verification when ingesting data.
Knowing which kind of BigQuery data type to use will help you create your data pipelines more easily.
It also makes configuring them within Panoply's BigQuery connector easy breezy. I would even invite you to use this article as a complement to the existing Panoply BigQuery documentation.
Once you better understand what data types are available, the quality of your reports will drastically increase in no time.
SQL types in BigQuery
BigQuery operates using structured query language (SQL), subdivided into legacy and standard categories.
It's good to point out that each subgroup has different data types and ways of questioning the database. When the hint is not informed, BigQuery will use standard SQL functions and methods.
If you're new to SQL hints, take a look at this Wiki to learn a little more about them.
To present what a legacy query looks like, I'll show a running example of a SQL command using the legacy category type.
SQL hint example
#legacySQL -- This hint informs that the query will use Legacy SQL SELECT weight_pounds, state, year, gestation_weeks FROM [bigquery-public-data:samples.natality] ORDER BY weight_pounds DESC;
Standard SQL is the type that you should be aiming to use when you don't have any constraints, such as legacy code on your lift-and-shift deployment.
Standard SQL also allows very nifty features like window functions and a more robust user-defined functions structure, and it's more flexible to create on standard SQL rather than legacy SQL.
It's also recommended, as best practice, to migrate your existing legacy SQL into standard SQL.
Google even offers a helpful page with guidance on this conversion. You can check out how to start it correctly here.
Standard SQL data types
The below table presents the possible data types when using the standard SQL category. I like to point out that standard SQL is the preferred category by Google, which means you can correctly assume that it has better performance and more options when compared to the legacy SQL category.
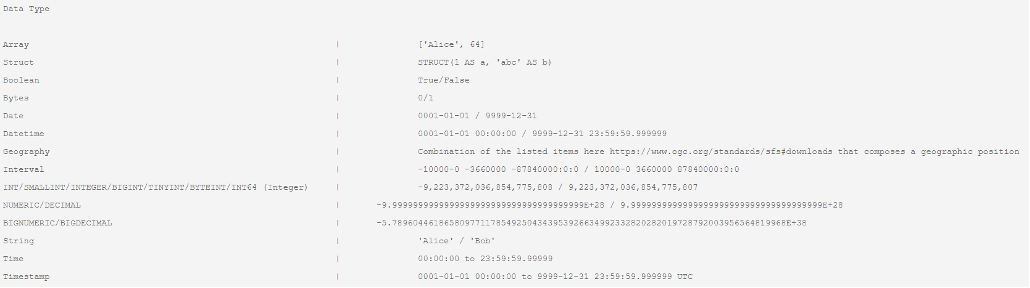 Standard SQL data types
Standard SQL data types
The standard SQL category accepts more complex data types such as ARRAY, STRUCT, and GEOGRAPHY data types. Any of the mentioned data types can order (or group) the results of any dataset; one of its severe limitations as the data types STRUCT and ARRAY are heavily used on streaming data ingestions.
Another example comes from the ARRAY data type not comparing its values with any field, which happens in STRUCT and GEOGRAPHY.
We can use ST_EQUALS as a "workaround" of comparing geographical values directly.
All other data types can filter SQL JOIN clauses and be used to order the results; always remember to cast the columns used to avoid unwanted effects explicitly.
Standard SQL also allows the usage of what is called "stored procedures."
The stored procedure allows the execution of repeatable functions—very useful for shareable business logic transformations between different departments.
For example, how the human resources department calculates profit benefits could be useful for the marketing department for calculating campaigns.
The benefit of well-defined data formats starts with your stored procedures—as options on the earlier stage of your analytics pipelines empower your analysts with a shorter reaction time to analyze your data.
Having these configured on your Panoply's integrations provides reports with a mature and concise data warehouse.
Legacy SQL data types
Legacy SQL uses the same data types as those used with standard SQL, excluding ARRAY, STRUCT, and GEOGRAPHY.
The NUMERIC type fields provide limited support, making it necessary to use an explicit conversion using the cast function when interacting with these fields.
The table below lists all the possible data types available when using the legacy SQL query category.
You can still access nested data using the "dot notation," but it doesn't allow nice tricks like generating your array on the runtime.
Legacy SQL will enable you to create reusable, shareable functions between different queries. It grants this possibility with user-defined functions (or UDFs); below, you have an example of a simple one.
UDF on legacy SQL
// UDF definition function urlDecode(row, emit) { emit({title: decodeHelper(row.title), requests: row.num_requests}); } // Helper function with error handling function decodeHelper(s) { try { return decodeURI(s); } catch (ex) { return s; } } // UDF registration bigquery.defineFunction( 'urlDecode', // Name used to call the function from SQL ['title', 'num_requests'], // Input column names // JSON representation of the output schema [{name: 'title', type: 'string'}, {name: 'requests', type: 'integer'}], urlDecode // The function reference );
So, since it has fewer available data types and some limitations like not being able to create shareable business logic as the standard SQL category does, the legacy SQL category is not a viable option.
Validating the target data type when inserting
To have a better understanding of the data types, let's look at some code.
We'll tackle the insert statement in the standard SQL category since it's the suggested category by the documentation, with a focus on the STRUCT data type. This data type can be challenging and very common when ingesting data from REST API payloads.
Also, I believe you might get bored with manipulations with Integers and Strings only. The following command inserts some data into the table DetailedInventory under the schema dataset.
The following SQL statement, written using standard SQL, will insert values on the mentioned table with some STRUCT types.
Insert statement
INSERT dataset.DetailedInventory VALUES('top load washer', 10, FALSE, [(CURRENT_DATE, "comment1")], ("white","1 year",(30,40,28))), ('front load washer', 20, FALSE, [(CURRENT_DATE, "comment1")], ("beige","1 year",(35,45,30)))
As simple as demonstrated, it inserts without any complexity (you can see how the inserted records look below).
Being able to run queries like this saves you the complexity of your ETL, enabling the possibility of creating orchestrated BigQuery questions or managing your BigQuery objects inside Panoply's data platform.
 Insert results
Insert results
When interacting with your data, you need to be aware of handling each data type properly.
One common mistake comes from comparing the time and time stamp data formats without the correct care. Although the two data types might resemble one another a lot, this mistake can result in inaccurate datasets.
Also, confirm that the function that you're using is under the right SQL category.
One good example is the cast function under legacy SQL and its reference under standard SQL, so know your terrain before making any changes to your code.
Conclusion
As we saw, the type of SQL used can block the usage of some data types.
Due to different ways of processing the data, there is a significant difference between legacy and standard SQL, making things far more complex than a simple "hint" at the beginning of the SQL.
Utilizing the correct data type can help you audit your data in its earlier stages. This could mean adding an automated reaction to insufficiently formatted data, saving your production support team some investigation. As the same response could take hours to identify the root problem, in addition to the time it takes to solve it once identified.
Sometimes you may even need to apply some predefined rules to treat your data based on learned processing problems.
Standard SQL should be preferred over the use of legacy SQL.
The latter doesn't have cool tricks such as windowing functions or better lexical support when creating your SQL statements (way better than the simple dot notation from legacy SQL).
This intel is killer when analyzing why your data still has bottlenecks during its ingestion.
If you still struggle to ingest your data pipelines, I want to invite you to look at how Panoply can help your team extract the most out of your Google Analytics data, or reach out to us if you still want something more from your data.



