Pressed by the end-of-year holiday rush, we all feel the pain of trying to do more. To help you get some time back, we've made our data warehouse even smarter—which means faster and more transparent.
We’re excited to share how you can see your database usage at a glance, control your data source refreshes and understand how Panoply improves performance.
Without further ado…
Q: Where can I see my current database size? I’m trying to understand my database usage…
A: You can find the current storage (from here on out, DB size) in the table page, like in the example below:
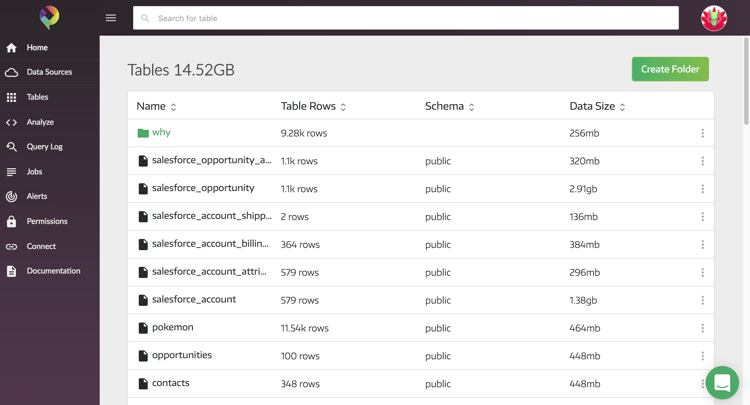
The DB size refreshes on a continual basis, so your db size should be current. As you might expect, DB size changes when you connect additional data sources and generate data through web app usage because automatic data loading and ingestion, especially when you use an ETL tool like Stitch with Panoply.
Q: How can I make sure my data source refreshes? I’m trying to figure out how to schedule data ingestion, can you help?
A: Of course we’re happy to help with data source scheduling. :) You can schedule your data source by clicking the click icon next to the data source.
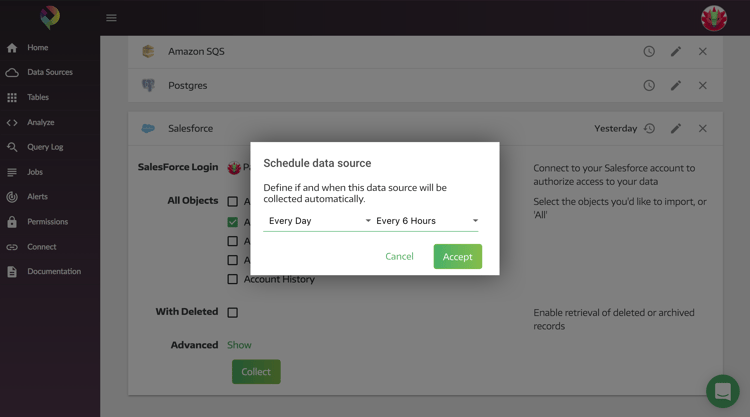
Panoply enables you to refresh the data in your tables on your schedule— you can set it to update daily, hourly, or on a specific hour of a specific day. Using this feature lets you keep your Panoply DB as up to date as your business requirements dictate.
If you happen to find that you need to update the data coming in from your data sources on-demand, you also have to option to open the data source and click “collect”. This updates the data source on demand without affecting your scheduled data source refresh, so using “collect” will be in addition to any scheduled data source refresh.
Q: What is an incremental key and why do I need one?
A: Technically speaking, an incremental key is a field that specifies the update time of a row or a running number that states the most up-to-date rows in comparison to others. This field can be used to collect only the most up-to-date rows, saving vast amounts of time in the collection process and improving performance.
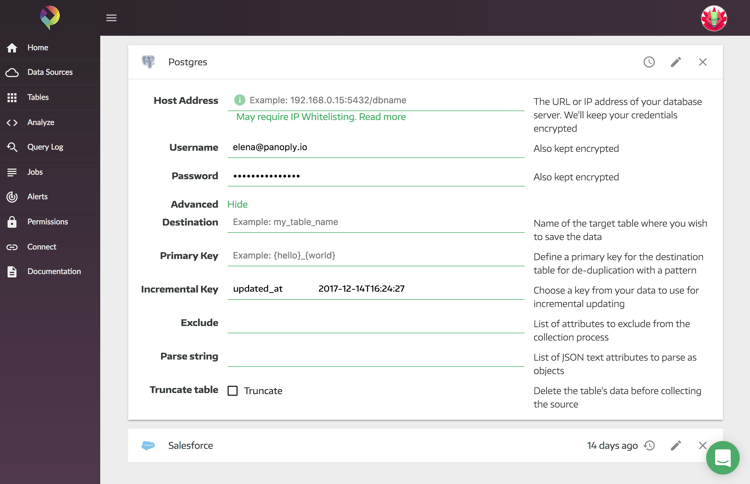
Incremental keys are great for providing shorter update times and faster scheduling. Panoply uses an incremental key to only pull the information that was updated since the last pull and then only updates the rows that have been changed. This means that we’re only updating the rows that have been changed, and not writing the same data to the table.
Here’s an example:
data (mysql)
| date | DAU |
| dec 1 | 23 |
| dec 2 | 25 |
| dec 3 | 22 |
| dec 4 | 10 |
panoply_data_source (mysql)
| date | DAU |
| dec 2 | (dec 1) |
| dec 3 | (dec 1 + dec 2) |
| dec 4 | (dec 1 +dec 2 + dec 3) |
with an incremental key
| date | DAU |
| dec 2 | (dec 1) |
| dec 3 | (dec 2) |
| dec 4 | (dec 3) |
| dec 4 midday | (no update - no changes) |
In most sources, incremental keys are already included, so there’s no need to make any changes. However, in some cases with some data sources, you might need to select your own incremental key to benefit from its advantages. Otherwise, Panoply will pull all of the data from within the source with every refresh.
We’ve only scratched the surface of your product questions. Please let us know what you think—Twitter, Facebook, Intercom, email, carrier pigeon—and if you have any other questions, please let us know. You might see one of your questions in a future post!



