Data as a Service (BDaaS) is a reality today. Increasing cloud usage, and new cloud services, mean you can set up data infrastructure that just works—without maintaining servers and with minimal setup and integration.
Why is a data platform as a service important?
Organizations undergoing digital transformation need to understand data. Until recently, the costs of setting up cloud data infrastructure have been prohibitive for mid-sized organizations, or those without strong technical expertise. Offerings by cloud and SaaS vendors are democratizing data. You don’t need a team of data experts to set up infrastructure—they’ll manage it for you, at affordable rates.
Three ways to do DPaaS
These three models for data infrastructure in the cloud mirror the three models of cloud computing:
- Data Infrastructure as a Service (IaaS)—“bare bones” data services from a cloud provider
- Data Platform as a Service (PaaS)—cloud-based offerings like Amazon S3 and Redshift or EMR provide a complete data stack, except for ETL and BI
- Data Software as a Service (SaaS)—an end-to-end data stack in one tool
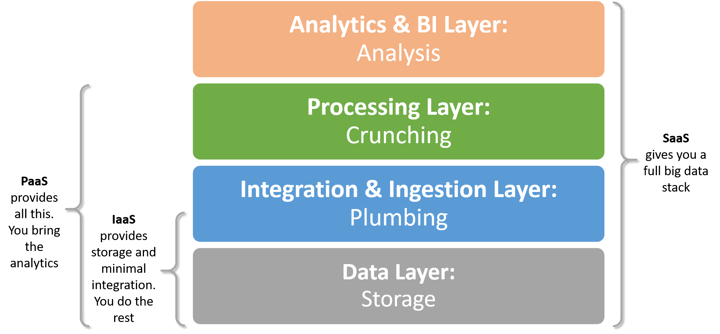
More comprehensive cloud services or SaaS means easier setup but less flexibility. Working with an end-to-end SaaS data system will typically limit the data you can use. PaaS or IaaS will let you tailor your BDaaS to custom data or workflows.
Data as a service—IaaS model
If you’re prepared to buy the engine and build the car around it, the IaaS model may be for you. One example is an AWS IaaS architecture combining S3 and EC2, from Amazon Web Services:
- Amazon S3, a data lake, can store unlimited amounts of structured and unstructured data.
- Amazon EC2, the compute layer, allows you to deploy any data service and connect to S3 data.
Options for implementing the data layer:
- Hadoop—run Hadoop ecosystem components on top of EC2 machines directly for full control
- NoSQL databases like MongoDB or Cassandra
- Relational databases like MySQL or PostgreSQL
(All of the above are self-managed, deployed independently as Amazon Machine Images.)
Options for implementing the integration/ingestion layer:
- Home-grown ETL scripts running on EC2 machine instances
- Commercial ETL tools running on Amazon infrastructure, leveraging S3
- Open source stream processing tools like Kafka running on Amazon machine instances
(The integration and workflow are on you.)
Data as a service—PaaS model
The instructive example (below) of a classic Hadoop-based cloud data infrastructure, managed entirely by Amazon, uses these three services:
- Data ingestion—log file data from Amazon CloudFront, but this could be any data source (using a service like Amazon Kinesis to ingest on-prem data).
- Amazon S3—data storage layer
- Amazon EMR—scalable pool of machine instances running Map/Reduce against S3 data
- Amazon RDS—hosted MySQL database storing Map/Reduce computational results
- Analytics and visualizations—via a BI tool you maintain.

A similar architecture is possible on the Microsoft cloud, using Azure HDInsight.
Data as a service—SaaS model
What does a data stack look like when it is fully hosted, from data storage to visualizations? Take this example from Looker of BDaaS in a SaaS model.
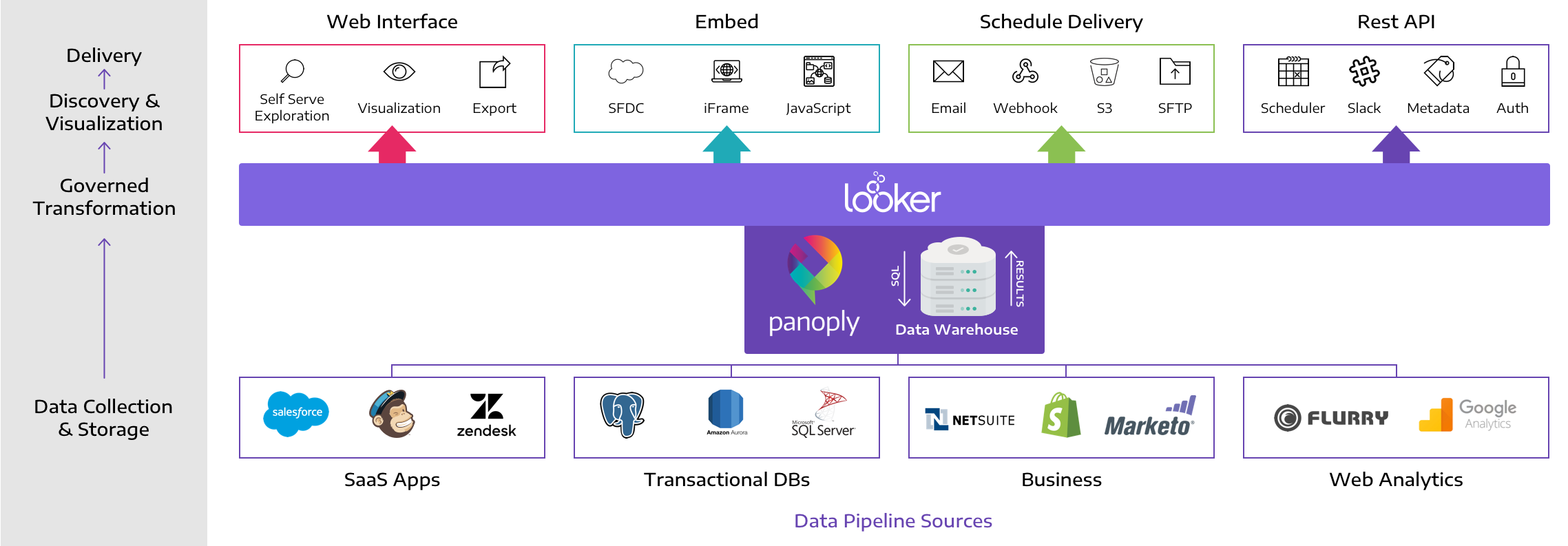
Looker (and similar tools like Power BI) handle the data pipeline from the database to BI visualizations:
- Data layer—data must be pulled into a standard SQL database. Panoply allows you to perform this stage effortlessly.
- Integration & Ingestion layer—Looker pulls the data from your SQL database into its Agile Modeling Layer
- Processing layer—Looker automatically prepares the data; you can provide custom business logic to guide transformations
- Analytics & BI layer—Looker provides full featured BI capabilities, including beautiful visualizations and dashboards
Comparing DaaS models: IaaS vs. PaaS vs. SaaS
IaaS model compared to SaaS and PaaS:
- IaaS is “hard core," more complex and often more expensive than other options
- Suitable for organizations with very complex data pipelines, or those moving existing infrastructure to the cloud
- Although IaaS is more difficult than other hosted models, it can be vastly superior to an on-premise data infrastructure.
- Lower upfront hardware costs.
Amazon, Azure and other cloud vendors provide a scalable, performant foundation compared to your own data center.
Most importantly, forget about maintaining the data storage layer. Goodbye expensive storage apps; hello Amazon S3 and Azure Blob Storage.
PaaS model compared to IaaS and SaaS:
- PaaS is the middle ground—you can offload most of the work to your cloud vendor, filling in any needed gaps.
You can still build custom data ingestion flows, and Bring Your Own BI.
This requires a higher level of expertise compared to SaaS options like Looker and Metabase.
SaaS model compared to IaaS and PaaS:
- Without complex organizational dependencies or data processes, there is little-to-no downside for smaller organizations or green field applications.
- Go from data to insights quickly, at low cost.
Switch to a more customized implementation via PaaS or IaaS model when you need power or custom processes.
Panoply—BDaaS platform offering the best of all worlds
Panoply integrates with your data sources, handles data ingestion, and automatically puts your data into analysis-ready tables, making it the best of all worlds—SaaS, PaaS and IaaS.
- Like SaaS solutions, you don’t need to figure out your data pipeline. Bring your data and you’re ready to analyze in minutes.
- Like PaaS solutions, you can use your BI tool of choice. Panoply does more than most PaaS solutions, as you don’t need to figure out integrations, data optimization, machine instances, clusters etc.
- Like IaaS solutions, Panoply is extremely flexible, supporting complex data ingestion processes and advanced transformations, on either structured or unstructured data.



