If you’re looking for a solution for processing huge chuncks of data, then there are lots of options these days. Depending on your use case and the type of operations you want to perform on data, you can choose from a variety of data processing frameworks, such as Apache Samza, Apache Storm…, and Apache Spark. In this article, we’ll focus on the capabilities of Apache Spark, as it’s the best fitted for both, batch processing and real-time stream processing of data.
Apache Spark is a full-fledged, data engineering toolkit that enables you to operate on large datasets without worrying about underlying infrastructure. It helps you with data ingestion, data integration, querying, processing, and machine learning, while providing an abstraction for building a distributed system.
Spark is known for its speed, which is a result of improved implementation of MapReduce that focuses on keeping data in memory instead of persisting data on disk. Apache Spark provides libraries for three languages, i.e., Scala, Java and Python.
However, in addition to its great benefits, Spark has its issues including complex deployment and scaling, which are also discussed in this article.
Spark Architecture
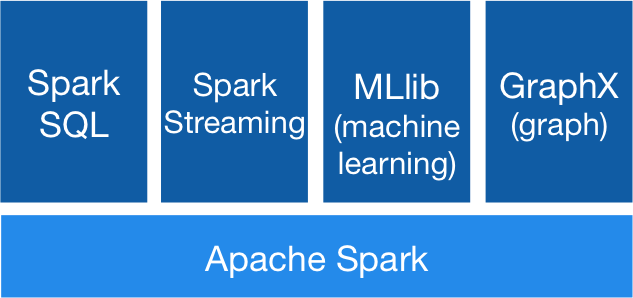
[img reference : http://spark.apache.org/]
The above diagram shows the different modules included in Apache Spark. Although primarily used to process streaming data, it also includes components that help you perform various operations on data.
Spark SQL: Apache Spark comes with an SQL interface, meaning you can interact with data using SQL queries. The queries are processed by Spark’s executor engine.
Spark Streaming: This module provides a set of APIs for writing applications to perform operations on live streams of data. Spark Streaming divides incoming data streams into micro-batches and allows your application to operate on the data.
MLib: MLLib provides a set of APIs to run machine learning algorithms on huge datasets.
GraphX: This module is particularly useful when you’re working with a dataset that has a lot of connected nodes. Its primary benefit is its support for built-in, graph operation algorithms.
Apart from its data processing libraries, Apache Spark comes bundled with a web UI. When running a Spark application, a web UI starts on port 4040 where you can see details about your tasks’ executors and statistics. You can also view the time it took for a task to execute by stage. This is very useful when you’re trying get maximum performance.
Use Cases
Analytics – Spark can be very useful when building real-time analytics from a stream of incoming data. Spark can effectively process massive amounts of data from various sources. It supports HDFS, Kafka, Flume, Twitter and ZeroMQ, and custom data sources can also be processed.
Trending data – Apache Spark can be used to calculate trending data from a stream of incoming events. Discovering trends at a specific time window becomes extremely easy with Apache Spark.
Internet of Things – IoT systems generate massive amounts of data, which are pushed to the backend for processing. Apache Spark enables you to build data pipelines and apply transformations at regular intervals (per minute, hour, week, month, and so on. ). You can also use Spark to trigger actions based on a configurable set of events.
Machine Learning – As Spark can process offline data in batches and provides a machine learning library (MLib), machine learning algorithms can easily be applied to your dataset. In addition, you can experiment with different algorithms by applying them on large data sets. Combining MLib with Spark Streaming, you can have a real-time machine learning system.
Some Spark Issues
Despite gaining popularity in a short time, Spark does have its issues as we will see next.
Tricky deployment
Once you’re done writing your app, you have to deploy it right? That’s where things get a little out of hand. Although there are many options for deploying your Spark app, the most simple and straightforward approach is standalone deployment. Spark supports Mesos and Yarn, so if you’re not familiar with one of those it can become quite difficult to understand what’s going on. You might face some initial hiccups when bundling dependencies as well. If you don’t do it correctly, the Spark app will work in standalone mode but you’ll encounter Classpath exceptions when running in cluster mode.
Memory issues
As Apache Spark is built to process huge chunks of data, monitoring and measuring memory usage is critical. While Spark works just fine for normal usage, it has got tons of configuration and should be tuned as per the use case. You’d often hit these limits if configuration is not based on your usage; running Apache Spark with default settings might not be the best choice. It is strongly recommended to check the documentation section that deals with tuning Spark’s memory configuration.
API changes due to frequent releases
Apache Spark follows a three-month release cycle for 1.x.x release and a three- to four-month cycle for 2.x.x releases. Although frequent releases mean developers can push out more features relatively fast, this also means lots of under the hood changes, which in some cases necessitate changes in the API. This can be problematic if you’re not anticipating changes with a new release, and can entail additional overhead to ensure that your Spark application is not affected by API change.
Half-baked Python support
It’s great that Apache Spark supports Scala, Java, and Python. Having support for your favorite language is always preferable. However, Python API is not always at a par with Java and Scala when it comes to the latest features. It takes some time for the Python library to catch up with the latest API and features. If you’re planning to use the latest version of Spark, you should probably go with Scala or Java implementation, or at least check whether the feature/API has a Python implementation available.
Poor documentation
Documentation and tutorials or code walkthroughs are extremely important for bringing new users up to the speed. However, in the case of Apache Spark, although samples and examples are provided along with documentation, the quality and depth leave a lot to be desired. The examples covered in the documentation are too basic and might not give you that initial push to fully realize the potential of Apache Spark.
Final Note
While Spark is a great framework for building apps to process data, ensure that it’s not overkill for your scale and use case. Simpler solutions may exist if you’re looking to process small chunks of data. And, as with all Apache products, it’s imperative that you be well aware of the nuts and bolts of your data processing framework to fully harness its power.



