Data warehouse technologies are advancing towards interactive, real-time, and analytical solutions. In particular, cloud-based data warehouse technologies have reached new heights with the help of modern tools like Amazon Athena and Amazon Redshift.
Comparing Athena to Redshift is not simple. Amazon Athena has an edge in terms of portability and cost, whereas Redshift stands tall in terms of performance and scale. Athena is portable; its users need only to log in to the console, create a table, and start querying.
Quick Overview
What is Amazon Athena and Amazon Redshift?
Athena is a serverless service and does not need any infrastructure to create, manage, or scale data sets. It works directly on top of Amazon S3 data sets. It creates external tables and therefore does not manipulate S3 data sources, working as a read-only service from an S3 perspective. Athena uses Presto and ANSI SQL to query on the data sets. It also uses HiveQL for DDL statements.
Comparing Athena to Redshift is not simple. Athena has an edge in terms of portability and cost, whereas Redshift stands tall in terms of performance and scale.
On the other hand, Redshift is a petabyte-scale data warehouse used together with business intelligence tools for modern analytical solutions. Unlike Athena, Redshift requires a cluster for which we need to upload the data extracts and build tables before we can query. Redshift is based on PostgreSQL 8.0.2.
When should you use Athena?
Amazon Athena should be used to run ad-hoc queries on Amazon S3 data sets using ANSI SQL. It can process structured, unstructured, and semi-structured data formats. It can also have data integration with BI tools or SQL clients using JDBC, or with QuickSight for easy visualizations.
When should you use Redshift?
It is recommended to use Amazon Redshift on large sets of structured data. It is scalable enough that even if new nodes are added to the cluster, it can be easily accommodated with few configuration changes. Because it contains a number of replicas, even if any node is down, it interacts with other nodes and rebuilds the drive. Redshift can be integrated with Tableau, Informatica, Microstrategy, Pentaho, SAS, and other BI Tools. It can be used for log analysis, clickstream events, and real-time data sets.
Athena vs Redshift: Base Comparison
Initialization Time
Amazon Redshift requires a cluster to set itself up. A significant amount of time is required to prepare and set up the cluster. Once the cluster is ready to use, we need to load data into the tables. This also comes with a lag time depending on the amount of data being loaded. In comparison, Amazon Athena is free from all such dependencies as it does not need infrastructure at all; it just creates its own external tables on top of Amazon S3 data sets.
Partitioning
Partitioning is important for reducing cost and improving performance. With Amazon Athena, partitioning limits the scope of data to be scanned. We can partition by any key, and usually we implement a multi-level partitioning scheme, for example, Street+Area+State+Country. The number of partitions in Athena is restricted to 20,000 per table.
Amazo Redshift has distribution keys that are defined while loading the data in the server. It is very important to properly define distribution keys as they may have further consequences and impact on performances.
UDFs
Amazon Redshift supports UDFs and UDAFs with scalar and aggregate functions. Python packages like Numpy, Pandas, and Scipy are supported with Python version 2.7. Although users cannot make network calls using UDFs, it facilitates the handling of complex Regex expressions that are not user-friendly.
Here is an example of Scalar UDF:
Create Function f_hostname (VARCHAR Url)
Returns Varchar
IMMUTABLE AS $$
import urlparse
return urlparse.urlpause(url).hostname
$$LANGUAGE plpythonu;
Amazon Athena does not have UDFs at all, thereby coming up short if the user has a very specific requirement that needs UDF implementation.
Primary Key Constraint
Amazon Redshift does not enforce any Primary Key constraint. We can upload the same data a number of times, however this can sometimes be dangerous as multiplied data can give inaccurate results. If we need a Primary Key constraint in our warehouse, it must be declared at the onset.
Amazon Athena works on top of the S3 data set only, therefore duplication is only possible if the S3 data sets contain duplicate values. Primary Keys in Athena are informational only and are not mandatory.
Data Formats and Data Types
Data Formats
Amazon Athena supports a good number of number formats like CSV, JSON (both simple and nested), Redshift Columnar Storage, like you see in Redshift, ORC, and Parquet Format. It supports all compressed formats, except LZO, for which can use Snappy instead. On the other hand, Redshift supports JSON (simple, nested), CSV, TSV, and Apache logs.
Data types
Amazon Athena supports complex data types like arrays, maps, and structs. Redshift does not support complex data types like arrays and Object Identifier Types. For more information on Redshift data types, click here.
Athena vs Redshift Pricing
Amazon Athena charges for the amount of data scanned during query execution. $5 is charged for a TeraByte of data scanned. Scanned data is rounded off to the nearest 10 MB. There is no charge for DDL, Managing Partitions, and Failed Queries.
Pricing for Amazon Redshift depends on the cluster, ranging from $0.250 to $4.800 per hour for a DC instance, or $0.850 to $6.800 per hour for a DS instance.
Additional Considerations
What is specific to Amazon Redshift?
- COPY
- Any row can be a maximum of 4 MB from any data source.
- VACCUM
- The maximum number of tables per cluster is 9900, including temporary tables; views are not limited. Similarly, the maximum number of schemas per cluster is also capped at 9900.
What is specific to Amazon Athena?
- MSCK REPAIR TABLE
- Serde
- The maximum number of databases is 100. Similarly, one database can contain a maximum of 100 tables. The number of partitions is limited to 20,000 per table.
- Query Timeout
Setup
Setting Up Amazon Athena
Only a few steps are required to set up Athena, as follows:
1. Create a database and provide the path of the Amazon S3 location.
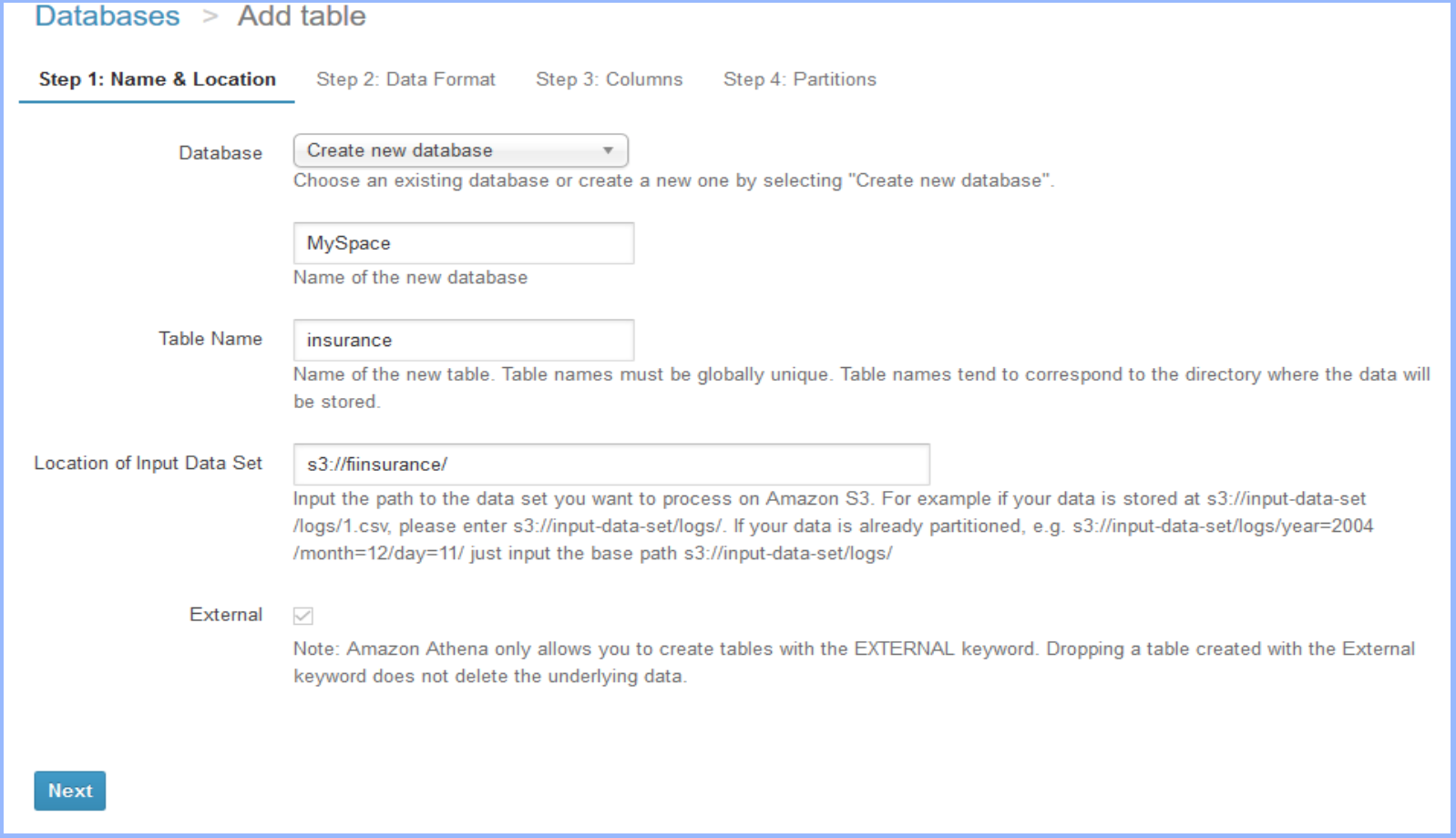
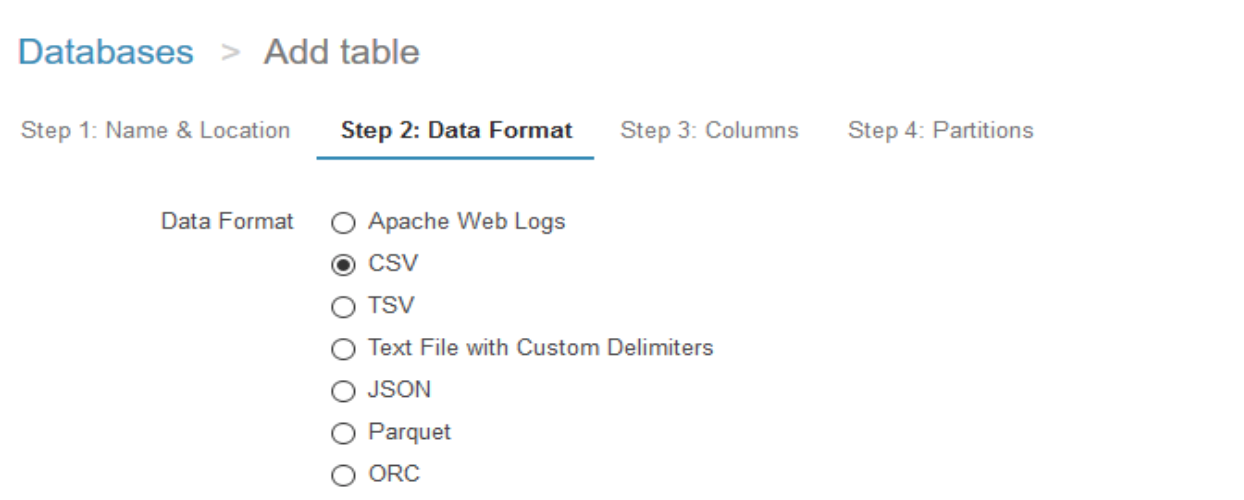
2. Specify the data format.
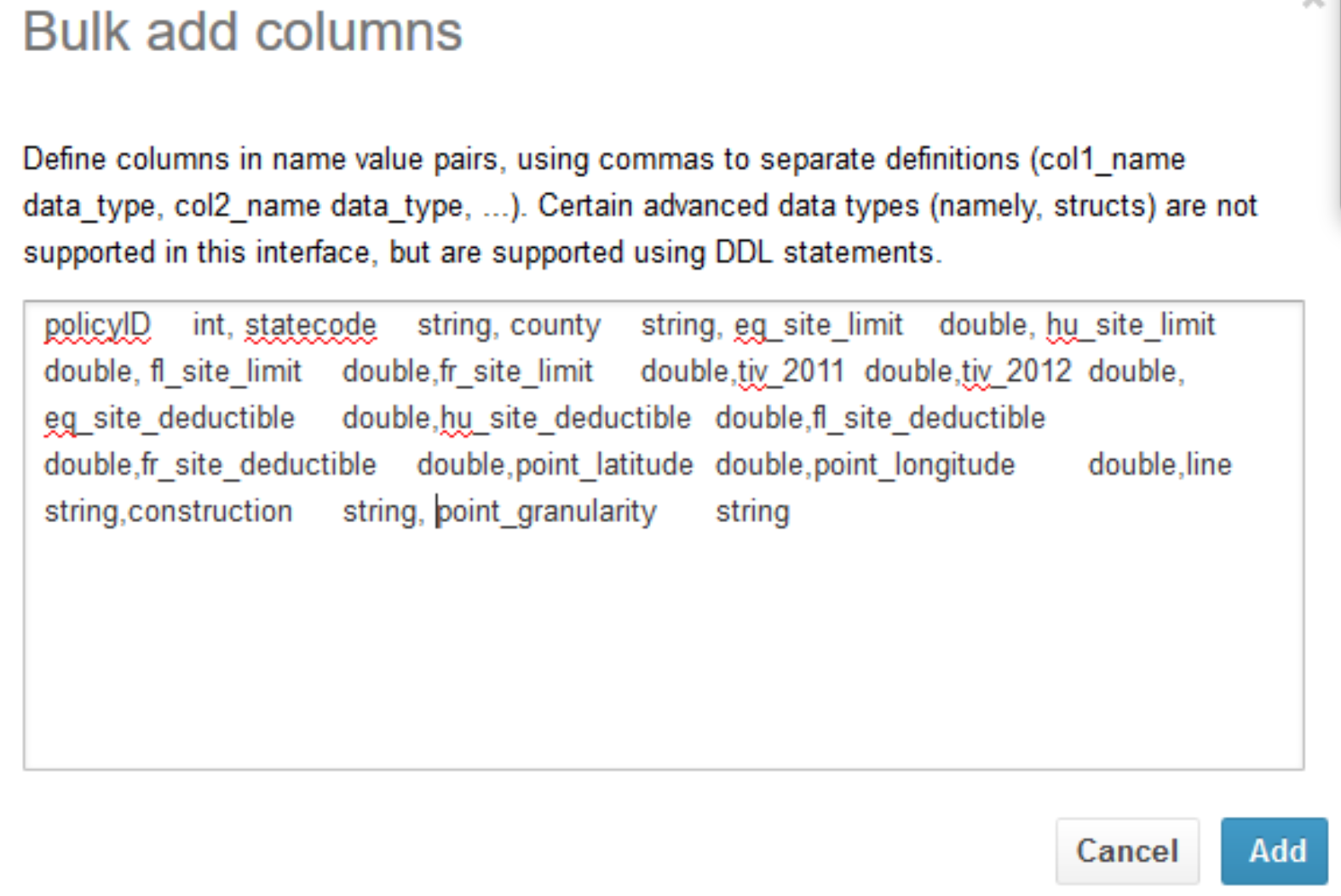
3. Create a table. You can create a table with discrete as well as bulk upload of columns along with data types. You can use only HQL DDL Statements for DDL commands.
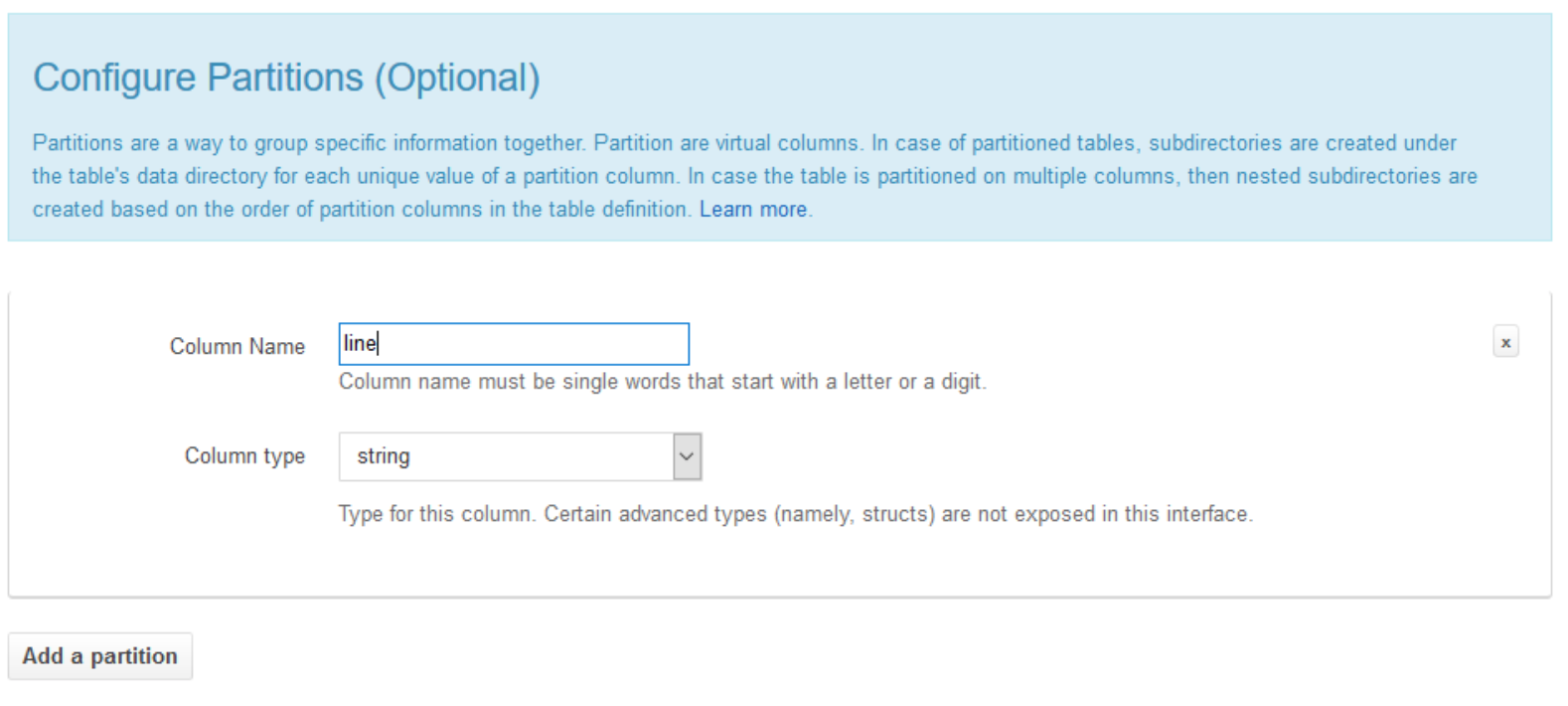
4. Even adding a partition is really easy.
Setting Up Amazon Redshift
As explained earlier, a cluster is required to set up Redshift.
1. First, configure the Redshift cluster properties:
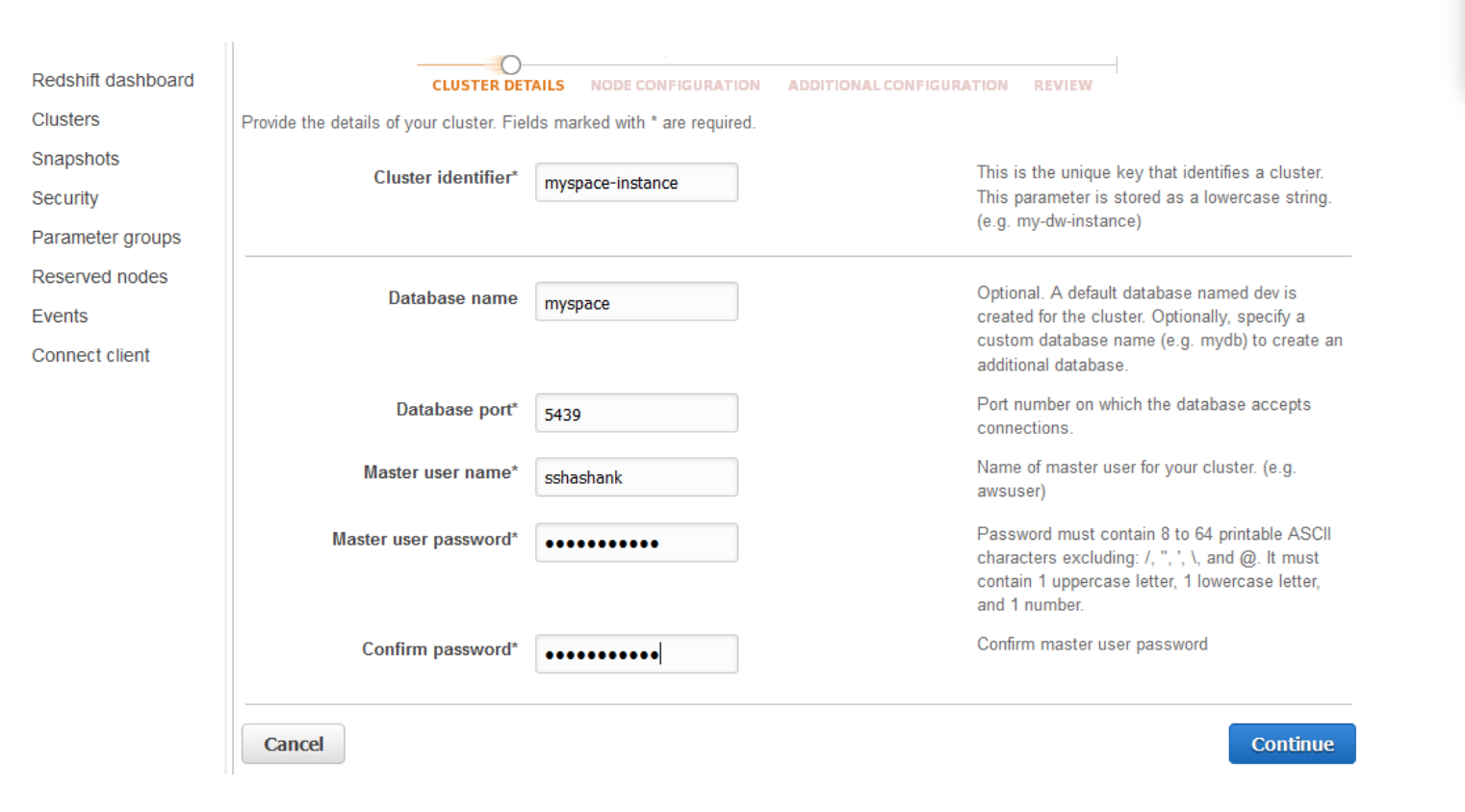
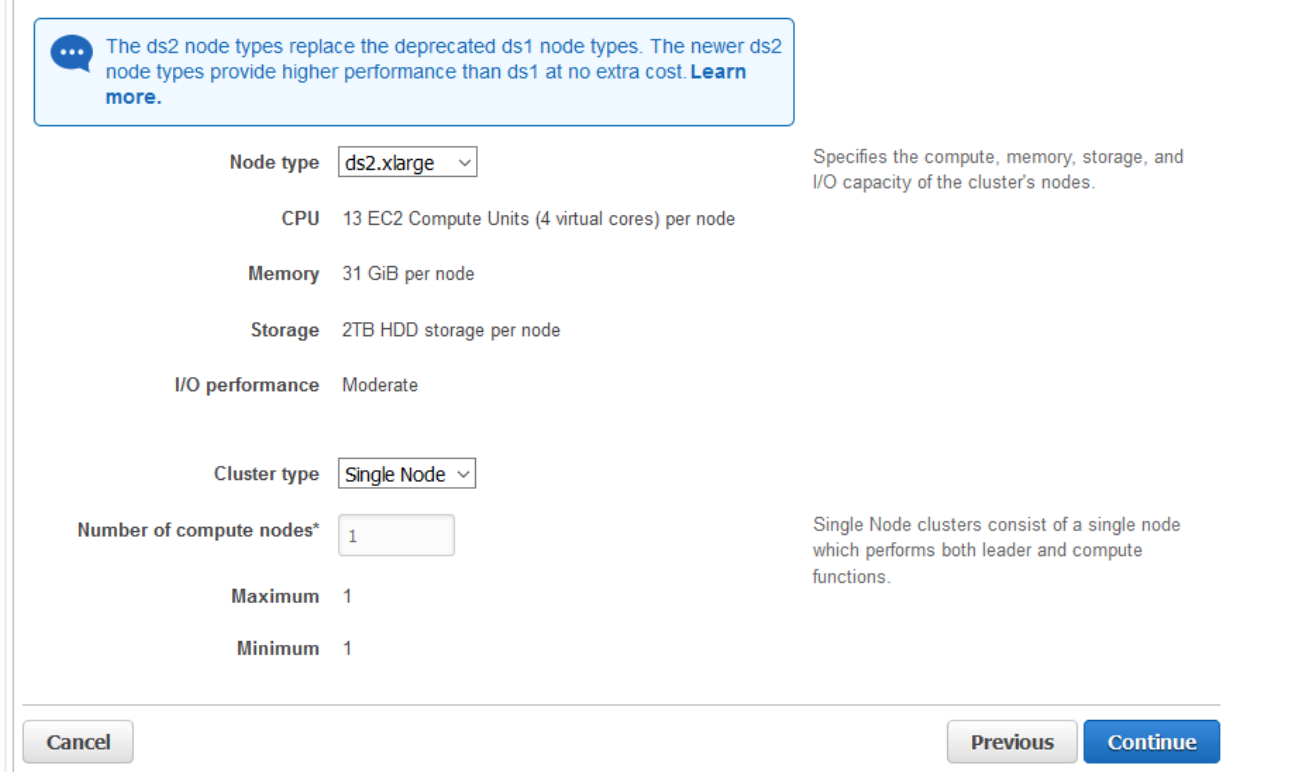
2. Specify the load type. The ds2 node type is also provided as an option that provides better performance than ds1 at no extra cost.
3. After setting up the cluster, wait a few minutes until the cluster is ready.
%20Redshift.png)
%20-%20Redshift.png)
In this case, 10-15 minutes passed before the cluster was ready to use.
Performance
To test query runtime performance on Redshift, we used SQL Workbench. Either Workbench/J or even Pentaho/Tableau can be integrated with Redshift. Athena doesn't need any editors like Workbench/J as results are shown directly on the console, making it portable and reducing dependency.
Create a Table
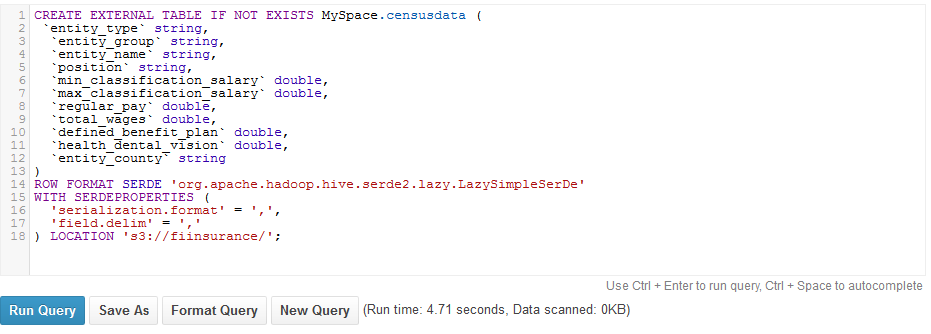
We created the same table structure in both the environments. For Redshift we used the PostgreSQL which took 1.87 secs to create the table, whereas Athena took around 4.71 secs to complete the table creation using HiveQL.
While creating the table in Athena, we made sure it was an external table as it uses S3 data sets. Secondly, we also defined Serde configurations. Serde is Serializer and Deserializer that accepts the data in Hive tables in any format, however the parameters need to be defined beforehand.
Redshift results:
.png)
Athena results:
Read
Query 1: Simple Select
We started by testing the normal scan speed of the data set. The same query was executed in both the environments.
With a simple where clause, we tried to filter out rows from the data set. Athena gave the best results, completing the scan in just 2.53 sec compared to 41.35 sec in Redshift.
Redshift results:
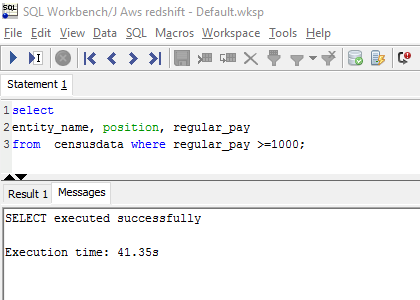
Athena results:
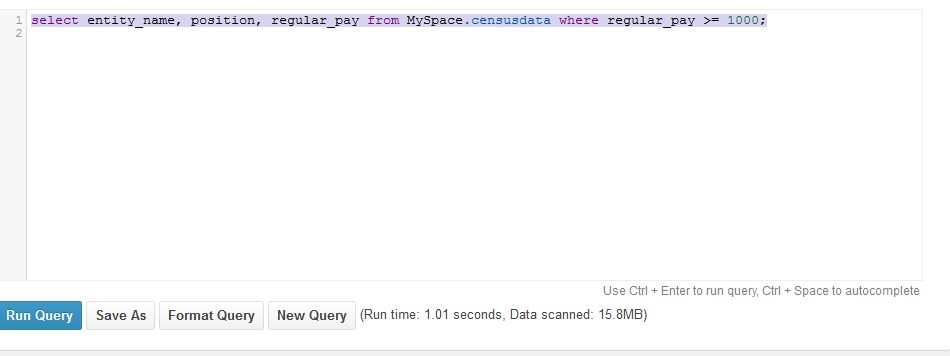
Query 2: Aggregation
Measuring an aggregation function is also an important aspect of performance. We used sum and avg functions.
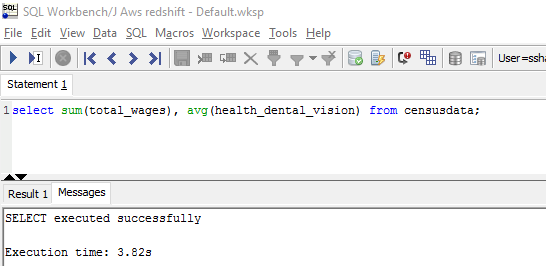
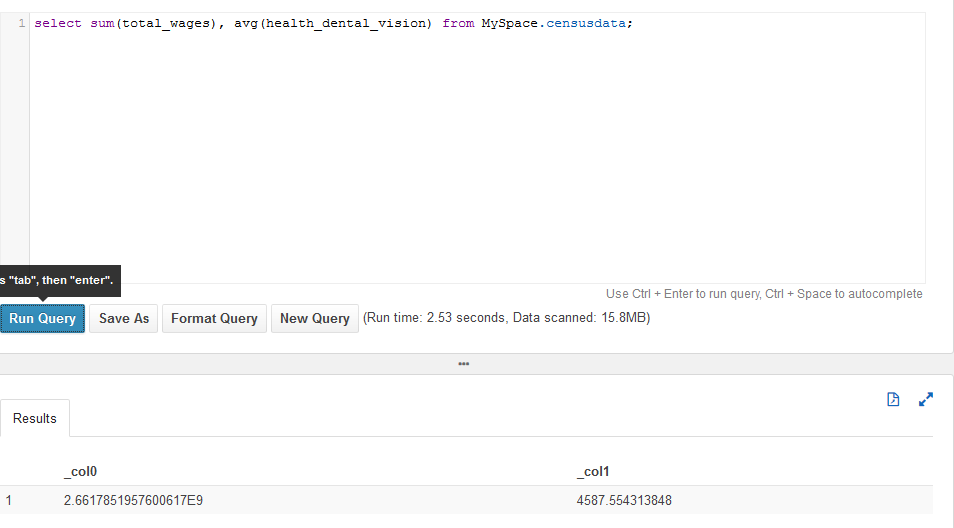
Again the winner was Athena, but with a fairly low margin compared to Query 1. Redshift finished in 3.82 sec compared to 2.53 sec for Athena.
Redshift results:
Athena results:
Query 3: Join
The next and most important parameter was complex joins and inner queries. As expected, Redshift scored on top of Athena. Redshift finished the execution in only 1 m,14 sec compared to 2 min, 11 sec with Athena.
Redshift results:
-1.png)
Athena results:
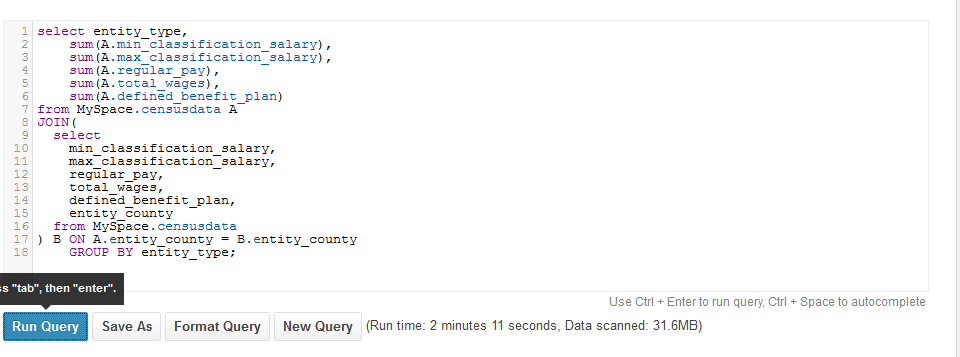
Disclaimer: Unlike Athena, Redshift requires the data to be pushed into the table with the help of a copy command. These results were calculated after copying the data set from S3 to Redshift which took around 25 seconds, and will vary as per the size of the data set.
Final Notes: Performance vs. Cost
With regard to all basic table scans and small aggregations, Amazon Athena stands out as more effective in comparison with Amazon Redshift. Athena does not require any installation or deployment on any cluster, queries with lower complexity should be triggered on Athena like filtering out based on partitions, queries without any inner queries. In case any ad-hoc queries need to be run, Athena seems the better choice as it provides ease of accessibility that is absent in Redshift. Even while loading, we might encounter lots of data type errors in Redshift as the maximum size of columns might not be known while defining the table, potentially resulting in errors while loading data. Nonetheless, when it comes to day-to-day queries, complex joins, and bigger aggregations, Redshift is the preferred choice.
In the case of huge numbers of transactions or larger data sets, Redshift would be scalable compared to Athena. Even adding more servers or even clusters is easily configurable on the AWS platform. Complex Joins or Inner Queries are better supported by Redshift due to its computational capacity.
Because Athena’s charges are based on the amount of data scanned in each query, it would be considerably cheaper if the data sets are compressed. Charges are rounded off to the nearest megabyte. Athena works hand in hand with S3, therefore adding up the charges for both of them will give the complete charges incurred.
On the other hand, Redshift costs are highly dependent on the type of instance used by the client. For Dense Compute cluster, such as dc1.large, nearly $0.250 per hour is charged. In the case of a dc1.8xlarge cluster around $4.800 per hour is charged. While we can opt for a Dense Storage cluster, ds2.xlarge adds up to $0.850 per hour and ds2.8xlarge charges $6.800 per hour. Tight management of the cluster and using compressed files can help reduce the amount of data scanned thereby decreasing costs. Finally, as we saw, Redshift is more likely to suit our needs when we have larger data sets and significant number of queries are triggered on the console.
Want to know more? Read Everything you need to know about Athena, Spectrum and S3.



