We tend to take it for granted that big data is changing the world, but how exactly does that happen?
Data scientists and data engineers are key players in the field of data utilization, and their different roles shape the ways this ever-expanding resource is exploited.
If you’re looking to get into data analysis or want to build a team that can implement it, you need to know what data engineers and data scientists do and how best to use their skills.
This article will explain why you might need to utilize big data. Then we will cover how data scientists and data engineers help you do so, how their roles differ, and where they fit into your organization.
Why use big data?
Using big data brings results—studies show data-driven organizations are 19x more likely to be profitable than others.
For example, Netflix monitors what consumers watch, how long they watch, when they pause, and other metrics. Then, it uses that data to recommend videos, achieving a huge user retention rate of 93%.
Achieving this kind of value isn’t easy, though. Only 32.4% of executives say they’re successful at the adoption stage.
Creating a data-driven culture is about more than throwing statistics around. You need to select the right metrics, ensure the data is accurate, and use insights to take meaningful action. Number crunching is only half the story.
Advantages of modern methods
Modern tools, such as Splunk or Panoply combine data from multiple sources and apply different analytics to it.
Screenshot from Panoply, showing a variety of data sources it can import
Simple tools like spreadsheets can do visualization and basic analytics, but they are limited in scope, vulnerable to duplication and error, and often narrowly focused.
For data to be most useful, it needs to be filtered, checked and verified, and piped to a data warehouse or similar location for analysis by specialists. This process provides advanced business intelligence, machine learning, or metrics that you can use to analyze how well your organization functions.
Where do Data Engineers and Data Scientists fit in?
Data scientists and data engineers perform different roles, but there is considerable overlap between the two.
- Data engineers are the builders, and the architects responsible for ensuring data is accessible to all stakeholders within an organization. They create the infrastructure that stores and moves data and the code that drives it.
- Data scientists analyze that data. They look for structure and relationships through statistical analysis and provide visualizations to explain the results to other team members.
In the US, data scientists and engineers have a typical salary range of $65,000 to $134,000, with the median at $92,000 for data engineers and $96,000 for data scientists.
Following are more details about how the two roles differ.
Data Engineers
Here are some specifics about what data engineers do.
Focus of the job
Data engineers design and implement the infrastructure that moves data around the organization.
They ensure the quality of data is high and control problems such as errors in format or unvalidated information.
Key responsibilities
Engineers build the infrastructure that allows data to be collected and moves it to a location where it can be analyzed, such as a data warehouse. They may also help develop the tools data scientists work with.
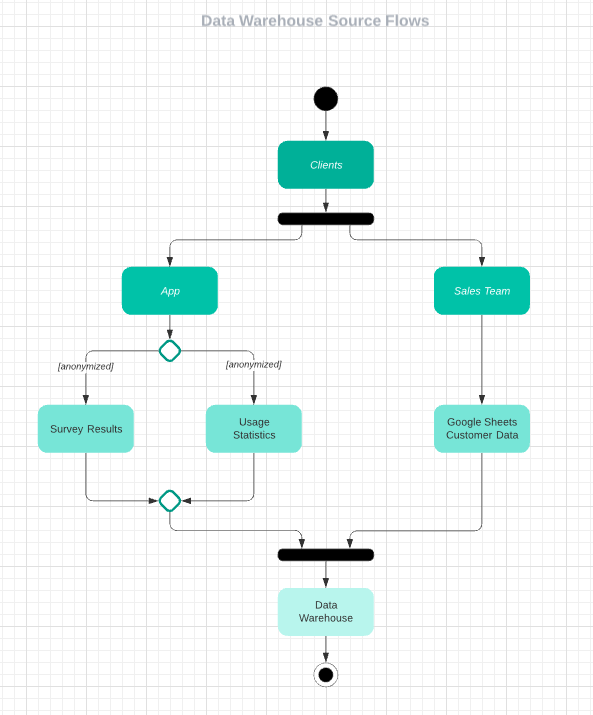
Chart showing data flow from clients to data warehouse
The infrastructure needs to be scalable and accessible to whoever needs it. In addition to data scientists, this could include analysts, managers, or engineers on other projects.
Typical day-to-day of a Data Engineer
Data engineers deal with a broad selection of software and hardware, which includes: databases, cloud tools, various programming languages, and different operating systems and network hardware.
Not all of their options will be optimal; they may, for instance, have to rely on the Access database that the sales department has been using for the past thirty years.
Their work can involve developing code and algorithms to move and process data. Troubleshooting and improving existing workflows is also a major part of the job.
They also liaise with stakeholders to service other needs.
Variations between companies
A data engineer's work will vary depending on the industry and company culture. For instance, scalability and rapid deployment are likely to be key considerations if you're in a growing web startup.
You might be the only engineer in smaller companies, perhaps working with a single data scientist—sometimes even playing both roles. In large companies, you'll be part of a team.
Occasionally, getting access to data will require negotiation, particularly in larger companies.
Educational/training requirements
A computer science background is the norm, with a computing or math-related degree being ideal. A general understanding of a broad spectrum of technologies is a big plus.
Demand is high, and transitioning from other software engineering or development roles is a common career path.
Specializations
There are multiple niches for data engineers to specialize in.
Working with big data is popular, and data engineers’ roles in this niche include building data pipelines and helping get code into production. In addition, data architects develop databases and related systems that meet business needs.
Machine learning, computer vision, and business intelligence are all specialty areas that require large amounts of data.
Keep in mind that there is debate about whether these specializations fall under the data engineer umbrella.
Key difference from Data Scientists
Unlike data scientists, data engineers are focused on getting the data and making it available. They are technicians first and foremost. Design, planning, implementation, and maintenance are the watchwords.
Data Scientists
Here is how the role of a data scientist compares to that of a data engineer.
Focus of the job
Data scientists analyze data to gain insights into their organization.
Since they have to translate data into actionable knowledge, data scientists tend to be more big-picture-focused than data engineers, with an understanding of what the data represents, what other departments need to know, and how their insights can translate into value.
Key responsibilities
A data scientist takes data as a starting point and uses it to produce information that helps stakeholders, internal or external, make better decisions. For example, the data can show which products and business practices work and which don’t, so companies know what to change.
Data scientists also liaise with other team members to determine what areas to focus on— making communication skills a big asset.
Typical day-to-day of a Data Scientist
Data scientists have more flexibility than engineers in choosing what tools and languages to use because they are given the data as their starting point and can decide how best to work with it.
Many data scientists describe the variety in their working day, for example, seeing a 40/30/30 percentage split between R&D, relationship building, and data analysis.
Python code, using NumPy and Matplotlib to generate a graph
Python and R are key languages for data scientists, though there are plenty of alternatives, and Julia has been making waves recently. Useful libraries to know are ggplot2 in R and Pandas in Python.
Variations between companies
Data science can vary hugely, depending on where you work. For example, scientists working with big data may handle anything from sales stats to medical records to engineering performance data.
Their work may involve analyzing similar data sets, refining algorithms to spot deeper patterns, or studying different data sets.
Educational/training requirements
Math, more specifically, statistics, is important to data scientists. A degree in computer science or a related field is also useful.
Some sources cite a master’s degree as a requirement, but that isn’t reflected in all job listings.
As with data engineers, demand is high. There are multiple paths to learning the needed skills, like bootcamps or self-guided courses, though the vast majority of professional data scientists have at least a master’s degree.
Specializations
There are several specializations that data scientists can choose from, including data visualization, data mining, business intelligence, and market data analysis.
Key difference from Data Engineers
Data scientists are concerned with how data is used and how best to share information with others, but they are less technically oriented than data engineers. Still, They need to be able to extract the most useful metrics and translate them into a form that people in other areas can understand and apply.
Conclusion
Data engineers and data scientists work closely together. So, when building a team, it is vital to make sure they complement one another well.
Getting the engineering side of things in place is key to helping data scientists work productively, so make sure you get the balance right when hiring.
As noted earlier, many tools are available for collecting and analyzing big data. When setting up data pipelines and analytical systems, a platform like Panoply can help. You can easily transfer data between platforms and use the analysis tools for the information you collect.
If you want to work with big data, Panoply can get you on the right track, and you can try it out for free.



