Congratulations! You’ve connected to your data warehouse (or database). You are on your way towards analytics awesomeness. But first, you need to get your bearings. Lucky for you, there are some pretty stellar data exploration features to get you started with just a few simple lines of SQL code. Data exploration, or data profiling, is the first step in sound data analysis. The point here is not to draw conclusions, but to get familiar with and understand the data you are working with.
In this post, I will walk you through the steps of exploring your data using Redshift. We’ll start at a meta level and then work our way towards more granular (detailed) information. I’ve ingested data from Facebook, Shopify and a couple of other data sources into my Panoply account and I’m curious about analyzing my Shopify data.
For this exercise, we’ll look at orders by country (we will refer to “country” as the country the order was shipped to). We'll start with PG_TABLE_DEF.
What is the PG_TABLE_DEF table?
PG_TABLE_DEF is a table (actually a view) that contains metadata about the tables in a database. PG stands for Postgres, which Amazon Redshift was developed from. PG_TABLE_DEF is kind of like a directory for all of the data in your database. It gives you all of the schemas, tables and columns and helps you to see the relationships between them.
PG_TABLE_DEF Data Dictionary (for our purposes)
| Label | Description |
| schemaname | Name of schema (container of objects, tables) |
| tablename | Name of database table (in schema) |
| column | Column name (in database table) |
The PG_TABLE_DEF view also provides information about how data can be stored in each column but for the purposes of exploring a Redshift data warehouse, this is what you'll need to know.
Select all rows from PG_TABLE_DEF
To get started, we will list all the columns in all the tables, in all the schema of our data warehouse for a 10,000 foot view of the data.
SELECT * FROM PG_TABLE_DEF
Output
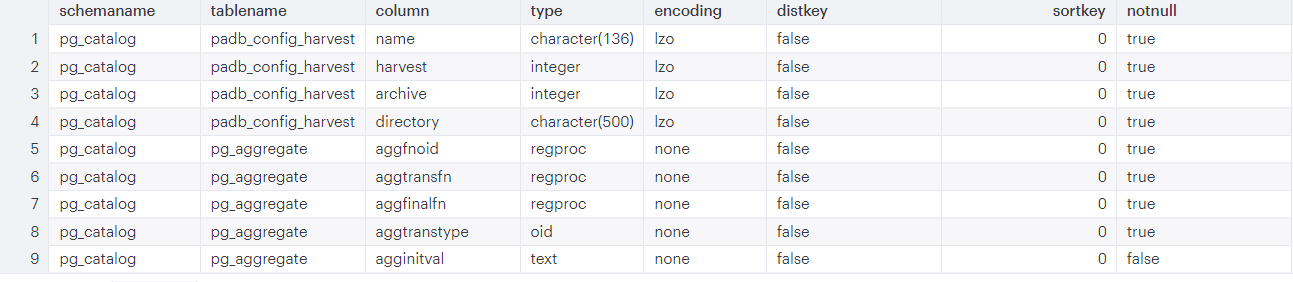
Schema and tables
PG_TABLE_DEF might return a massive number of rows. For our purpose of basic data exploration, we will focus on schema names, table names and columns. You may want to look at the table names within a particular schema. Simply put, schemas are like containers of objects (in our case tables) that keep your data warehouse organized.
The following query gives you a list of the distinct (unique / non-duplicated) table names from the PG_TABLE_DEF table contained in the public schema. By default, every database has a schema named “public”, and all users have CREATE and USAGE privileges on the public schema. If you want table names from all schemas, omit the WHERE clause in this query. If you want results from particular schemas, change the WHERE clause to: WHERE schemaname IN ('public', 'pg_catalog', 'xyz_schema_name').
Select all distinct table names in a schema
SELECT DISTINCT tablename FROM PG_TABLE_DEF WHERE schemaname = 'public'
Output
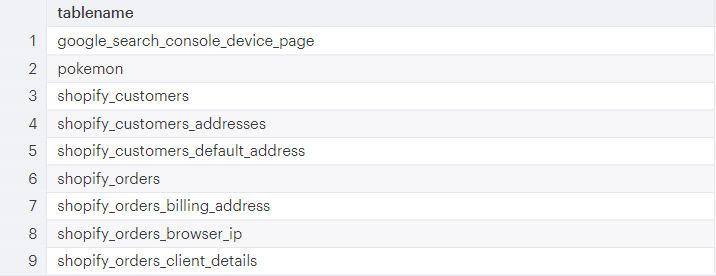
Getting warmer…
As you may recall, I’m interested in Shopify orders by country.
This query will give me all tables ingested from Shopify related to orders
SELECT DISTINCT tablename FROM PG_TABLE_DEF WHERE schemaname = 'public' AND tablename ILIKE '%shopify%' AND tablename ILIKE '%orders%'
How does this query work?
It selects all of the unique table names from the PG_TABLE_DEF table where the schema name is “public” AND the table name contains “shopify” and “orders”. The % is called a “wildcard” which means it refers to any character or set of characters. Because there is a % before and after ‘shopify’, the results will include any table name that contains ‘shopify’ regardless of whatever comes before or after it. Table names included in our results must also include ‘orders’ (could have any character or set of characters on either side of the text). ILIKE (as opposed to LIKE) is not case-sensitive.
Output
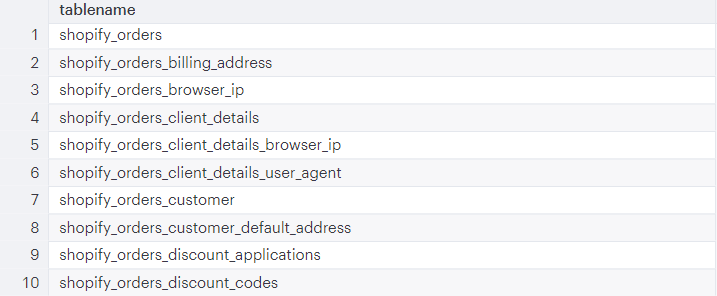
Next step: find your data
Find a table (from the list above) that has a column with “country” in the column name
SELECT
DISTINCT tablename, "column" FROM PG_TABLE_DEF WHERE schemaname = 'public' AND tablename ILIKE '%shopify%' AND tablename ILIKE '%orders%' AND "column" ILIKE '%country%'
Note: You will need double-quotes (“) around “column” so that it will not be interpreted as a keyword.
Output
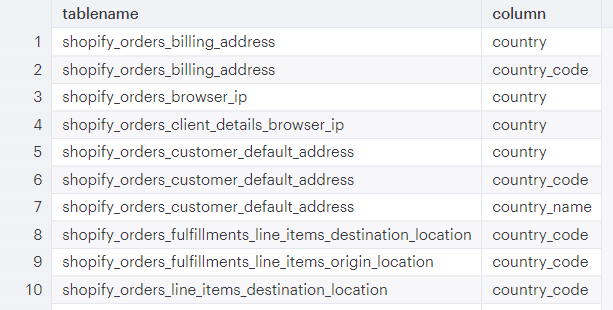
Each of these tables has a column with “country” in the column name. To explore the tables individually, SELECT * FROM table_name.
Next step: explore a table of interest
Select the top 10 rows from “shopify_orders_shipping_address” table
SELECT TOP 10 * FROM shopify_orders_shipping_address
This query helps us to see what information is in the shopify_orders_shipping_address table.
Note: if you are using Mode Analytics or a SQL editor that has a “limit” box, you may have to uncheck it before running this query. A query cannot have multiple LIMIT clauses (the checked box means LIMIT 100 rows).
Output (edited)
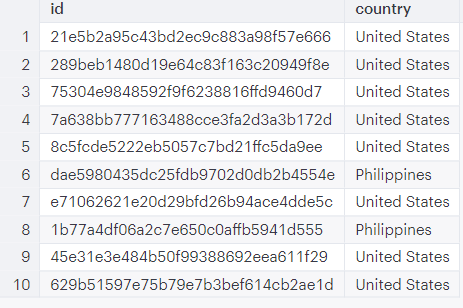
A couple of things to note:
- I limited the columns to “id” and “country” for this post (to respect confidentiality).
SELECT TOP xorLIMIT xwill return rows in the same order as they are listed in the table. If the table is sorted, it will return rows in the sorted order. If the table is not sorted, the returned rows will not be sorted.
SELECT TOP 10 id, country FROM public.shopify_orders_shipping_address
This query would yield the same results because “public” is the schema that contains the table “shopify_orders_shipping_address”.
Drill down: find an interesting column
Select distinct values of an interesting column
SELECT DISTINCT country FROM shopify_orders_shipping_address
This query returns each unique value from the “country” column in the “shopify_orders_shipping_address” table.
Output:
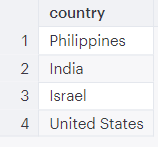
Aggregate values in an interesting column
Once you’ve explored the values in an interesting column, you can aggregate (group) them.
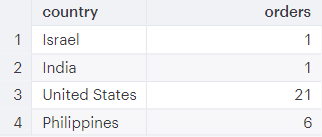
Group Shopify orders by country - BINGO!
SELECT country, COUNT(id) as orders FROM shopify_orders_shipping_address GROUP BY country
This query returns columns named “country” and “orders”. “Orders” contains the total count of order “ids” from the “shopify_orders_shipping_address” table. The results are grouped by country. You can see that most Shopify orders were shipped to addresses in the United States.
Output:
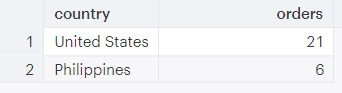
Filter rows that contain an interesting value in a column
Select orders shipped to the United States or the Philippines (only).
SELECT country, COUNT(id) AS orders FROM public.shopify_orders_shipping_address WHERE country IN ('United States', 'Philippines') GROUP BY country
The WHERE clause limits our results to orders that have “United States” or “Philippines” in the column called “country”.
Output:
Bon Voyage!

I hope this post gave you some tools to start exploring your data. My intention was to help you get “the lay of the land” with a more meta overview (PG_TABLE_DEF) and then give you ideas about how to hone in on values of interest. I know from experience, learning SQL can be overwhelming. It’s helpful to start with simple queries (and take breaks)! I encourage you to practice and get comfortable with your own data. This is a great way to get started.



