Data and music have much in common given that both tell stories with points and notes, yet each on its own lacks the coherence and context that distinguishes music from noise. Paradoxically, in the modern world of music and data, noise has become the glue that binds both data and bits.
Dithering is an intentionally applied form of noise used to randomize quantization error, preventing large-scale patterns such as color banding in images.
In the audio digital domain, dithers are used for the same purpose but to reduce the bit-depth of an audio. Surprising as it may be we add noise on purpose, and as you’ll soon see that’s a good thing. Bit-depth defines the number of measurement values describing the amplitude of a single audio sample where each bit represents 6db of dynamic range. For example, a recording made at a 24 bit-resolution would have a potential range of 144 db (24bits X 6db = 144db). In real world application this is how we perceive different volumes.
When we reduce bit-depths we are reducing the number of values available to measure the amplitude of the given sample. As a result, certain values will be forcibly rounded off to the next closest value. This can create an audible distortion where the values have been rounded, squaring off the waveform. Obviously this distortion is a bad thing and to compensate for it we provide our audio with a subtle white noise before reducing the bit-depth which eliminates the truncation distortion. This is known as dithering; Adding “unnatural” additions that will improve the final results when processing any given input. These additions aren’t valuable in themselves, but are an asset when added to an existing element.
Admittedly listening to just white noise can be a nerve-racking experience, but there is no denying the critical effect it has on the final outcome. More importantly, this technique can be applied to the data warehousing domain. By “polluting” our inputs we can achieve a significantly superior final result both in functionality and agility and with a higher degree of control. With that, let’s discuss the different types of “noises” that can be applied to data.
Destination Patterns
Let’s say you’re planning on going white-rafting with a few friends, but you are a big group of people so there wouldn’t be enough space for everyone on one dinghy. To avoid the scenario where one of you would be separated from the group you can’t show up without previous planning. So you’ll need to understand the situation before the event, research how much people can fit in a dinghy, and pre-divide the group so minimum each dingy will have no less that two people from the group. Everyone will know in advance to which dinghy he should go and their destined travel group.

Let’s move on from the allegories and look at some real data examples. To keep this simple let’s assume that we’ve already retrieved active user attributes information and their activity data with some RESTful API. In addition, each user has a mailing_listname property, that points to the relevant mailing list which he is associated with. Now to group users by mailing lists we’ll address each mailing list as a separate table listing all associated users. To achieve this we need a way to dynamically control each user’s destination based on their mailing list. Meaning that each input (user) should contain information regarding its destination in a predefined pattern so that in later processes each input will be sent to its target table. To define the process flow, we first need to identify the relevant field (in our case mailing_listname), and then apply it as the value for the predefined destination pattern, e.g., __tableName. Later, we will be able to identify the predefined pattern which we defined in the beginning and apply the destination name for each input .
Let’s look at an example. First, we need to define the destination pattern:

Our pattern describes that each input is part of the users collection, but targeted to different tables depending on its list name. The string ‘{__tablename}’ is dynamic and should be replaced at a later point in time by each list name.
So our retrieved raw data will look something like this:
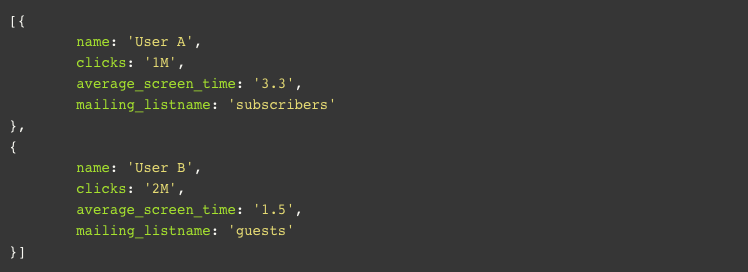
And with our additions applied:
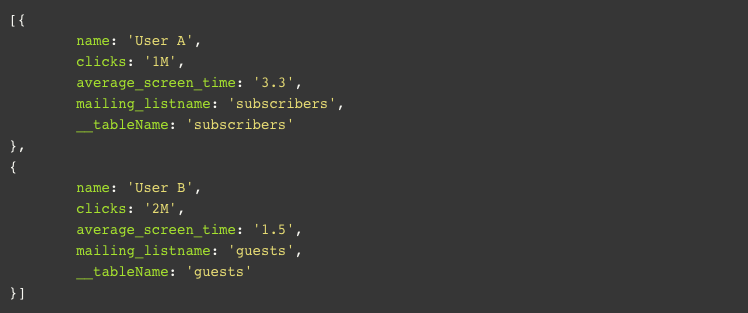
At this point, each input should have been applied with the predefined pattern functioning as the destination group property indicator. Now we can use this property to set the exact target table name. Remember, we used a variable named destination which converts to ‘users_{__tablename}’ as our destination pattern, so now we can just assign the relevant value as per our pattern:

The result is that we now have the __dest property for each input, meaning each object has been tagged with its relevant table name to which it belongs. The first input will go under a table named ‘users_subscribers’ and the second one will go to ‘users_guests’. This way, our tables become truly dynamic in the sense that the attributes define their shared quality. We can group different inputs from different API’s to shared tables or make a distinction between different collections, all within an automatic process. We can even take this logic one step further for more advanced and targeted results. For example, identify user activity by their latest active month and group the tables by each month or by a given shared ip address for each input we can create tables based on location. To add a tad more complexity to the previous example let’s say our users now contain the following information:

We can analyze ip_address for each user and target him to his associated table by location.
The “white noise” we added to our inputs helped us arrange it to better fit our purposes and increase our overall potential to reason with our data and better understand it. However, some additions are more than nice to have, but critical to our insert and upsert processes. For example, event based data is driven by time and date information which needs to be handled carefully or we’ll end up erroneously updating existing inputs. In the domain of messaged events with Amazon SQS, events are not necessarily received by the order they were sent. An event with a given id of ‘event1’ could have entered the queue twice, each with different results for the same event. This can create a situation where events are received in the wrong order, with the first being outdated but received last. To compensate, we need to apply a property that enables us to order those and update each accordingly. Given an event with an attribute named SentTimestamp we can use the property as follows :

When we finish with a set of events we can order the values:

Now that each event is ordered by its sent time property we can use it to make our update process correct by using our __sent_time property to update the same events (with the same ids) in their correct order in which they were sent to the queue. With our __sent_time property we can also identify outdated events and store them directly to a history table. Without our “white noise” additions, we could have had false values influencing of decisions.
These examples are just the tip of the iceberg. There are many more additions and techniques you can apply to a given input or inputs in reference to their shared attributes. The main takeaway here is that that there is no need to be afraid from “polluting” your inputs as long as it’s done consciously and in the right places. When done right, you can extract more from your inputs for deeper insight. The manner in which audio technicians use dithering so that their materials will be playable and supported in all platforms, with unnoticable quality damage, can and should be adopted in analytical data software to capture the depth behind flat inputs and attributes and draw profound conclusions.



