If you're collecting data in a warehouse, you may have come across many data sources and formats. To combine these many formats, you may need to go through the ETL process. In other words, you may need to extract data, transform formats, and load the data into your data warehouse.
As we've described here, coding this process by yourself can be tricky. The easy way out is to use an off-the-shelf ETL tool that'll do the hard work for you. However, picking the right tool can be difficult, as a number of choices are available.
In this post, we've put together a list of top ETL tools focusing on MySQL data pipelines. This list will help you find the right tool for you. That way, you can make sure your project goes off without a hitch.
10 Top MySQL ETL Tools
We've ordered the tools from most broadly appealing to most specialized in their operations. Let's look at these one by one.
1. Panoply
Panoply gives you a cloud-based, low-code platform to manage your data warehouse and ETL process. Bundled with a stack of data connectors and integrated storage, Panoply can connect you to a variety of sources, from Twitter Ads to Shopify. You can simply connect your SQL data sources using the MySQL connector. And you can store your data in a managed data warehouse. Once you've stored the data, you can explore and analyze the data on Panoply's workbench or your favorite business intelligence tool.
Behind the scenes, Panoply uses ELT (Extract, Load, and Transform) in place of the traditional ETL. In short, ELT avoids the potential delay in the transforming step to improve overall efficiency. If you're curious about the details, we've explained the nitty gritty of it here. With built-in dynamic processing capabilities, Panoply will become your in-house data engineer in no time. Plus, Panoply will manage your data warehouse, so you won't need to set up storage on your own.
You can take a sneak peek into flexible and effortless data management by trying out Panoply for 14 days with unlimited features.
2. Talend
Looking for an open-source tool for your data integration? Talend comes in both open-source and enterprise modes to support your ETL needs. The platform has an interactive interface, with drag-and-drop features to build your data pipelines. Since it's built in Java, you can use Java code to connect databases, including MySQL. The platform supports connecting to a vast number of databases and can be used for quick ETL operations.
Although the platform offers Java-based controls, you may need a separate resource to handle the tool as needed. As a result, Talend may be best suited for more technical users to get the most out of it. Moreover, if you choose the open-source tool, you may have to rely on the open-source community to resolve any issues you may run into. And that may be frustrating and time consuming.
3. Pentaho Kettle
Kettle is the ETL tool in the Pentaho data suite. Pentaho is now part of Hitachi Vantara.
In a similar fashion to Talend, Pentaho has both open-source and paid versions. In Kettle, you can use many data input formats to store data in your chosen data warehouse. You can use JDBC connections to connect MySQL sources as well. The interface gives you an overall view of the entire process while letting you manage separate jobs easily.
Setting up Kettle for the first time may not be the most intuitive thing to figure out. For this purpose, you may need technical experts to handle the platform. Besides, you may have to count on online community support if you choose to go forward with the open-source version.
4. Domo
Domo is a cloud-based data integration platform. It includes data analytics, visualization, and automations along with its ETL capabilities. You can create pipelines with drag-and-drop components, combine large datasets, and explore data within Domo itself. And you can use MySQL scripts to customize your data pipelines as well.
Nevertheless, the initial setup of the Domo platform could be far from easy. You may need a skilled team to set up and test the initial pipelines.
5. Hevo Data
Hevo is a no-code data pipeline that offers a set of promising features. It transfers your data in real time and comes with a number of built-in integrations. What's more, it allows you to continuously monitor your real-time data pipelines with ease.
Hevo has free and paid versions available. While the free version is limited to 5 million events per month, the paid version starts at $249 for 20 million events.
6. Blendo
Blendo is another no-code, cloud-based data integration platform. It connects a number of data sources, such as Facebook Ads and NetSuite, to data warehouses such as Panoply and Microsoft SQL Server. In addition, you can explore data using a set of analytics tools and automate synchronizing with data sources.
Blendo offers free and paid plans. The paid version starts at $750 for 25 million events per month, which could be expensive for a small-scale business. On the other hand, the free version has only three data sources and three users allowed on the platform.
7. Skyvia
Skyvia is a cloud-based platform hosted on Microsoft Azure cloud. As a no-code ETL tool, it allows you to import data from sources and export to target databases. These sources and targets can be CSV files, databases, or cloud-based applications such as Dropbox or Asana.
In addition, Skyvia lets you sync data automatically among sources. Imagine you need to keep a local up-to-date copy of your Salesforce data in the cloud. Skyvia can help you automate replicating cloud data to a local data warehouse of your choice.
Skyvia has a free plan for you to get started with. At 5,000 records per month and five query runs per day, its functionality is somewhat limited. For a commercial enterprise, you may need to use a paid plan to get the best out of the platform.
8. FlyData
FlyData (now Integrate.io) is surprisingly specific in its functionalities. It moves your data from sources such as MySQL and PostgreSQL to Amazon Redshift warehouses. The data pipelines support near-real-time data synchronization and automatic error handling. You can easily set up the platform to suit your ETL needs. FlyData provides a secure tunnel to ensure your data security and provides reliable technical support as well.
FlyData may be for you if your warehouse is specifically Amazon Redshift. Pricing is based on the number of rows, and is $657 for 40 million rows per month.
9. Apache Spark
Apache Spark is primarily a data analytics engine that can efficiently process large datasets. What's more, it's an open-source tool you can use to build data pipelines using code.
Since Apache Spark supports a variety of languages, including Java and Python, you can easily write your own database connection to connect MySQL data sources. Furthermore, Spark lets you use various analytic and machine learning techniques to explore your datasets.
Given that it's a powerful data engine, Spark is for you if you need to perform a number of complex operations on your collected data, but you may need dedicated engineers to manage and handle your data flows and integrations.
10. AWS Glue
AWS Glue is for you if you have an Amazon Web Services ecosystem and a serverless environment. It's a cloud-based tool built using Python. Offered by AWS, it has both a visual interface and a code-based environment for you to manage your data flows. If you already have AWS in your data pipelines, AWS Glue will seamlessly connect with your existing environment.
However, pricing may be a concern with AWS Glue, as you may be billed by the second at an hourly rate. Furthermore, you may need a complete serverless environment to use AWS Glue and have in-house expertise to manage the platform.
What's the best choice for you?
To sum up, there are a number of ETL tools to help you build MySQL data pipelines. Choosing the tool that's just right for you depends on different factors. These include the amount and type of your data and the operations you wish to perform on them.
Let's compare these tools:
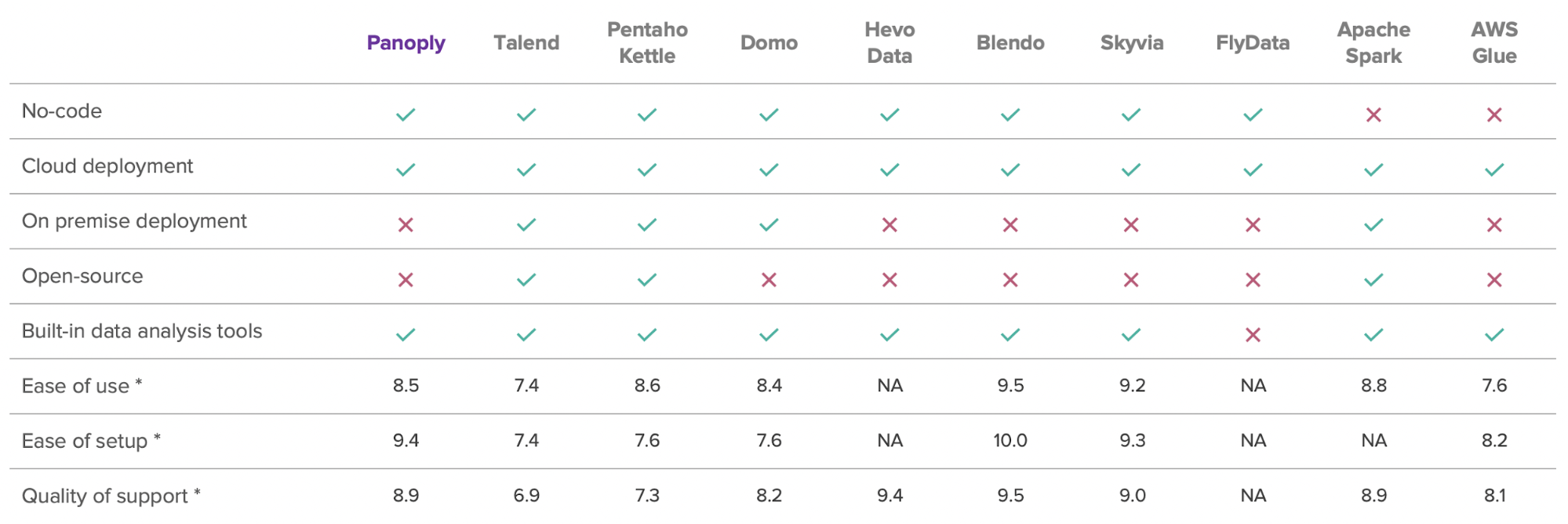
Values obtained from G2.
Nonetheless, if you prefer a no-code and straightforward ETL tool to manage your data in the long run, Panoply will help you out. The 14-day trial lets you explore the platform and experience how it'll work out for you.



