The byproduct of the ever increasing integration of the internet in our daily lives is massive growth of data transitioning between applications and servers every minute. In order to make these transitions fast we needed data structures that are less demanding on storage and compute.
JSON is a semi-structure data model that answers our need. Its simplicity and wide support by many programming languages has made it the data model of choice to facilitate these transitions. Now, I want to say that semi-structure data is schema-less, but that’s not always true. What is true is that we are not required to predefined rigid schema for the JSON collections. Here are some examples:
- We can change the attribute type between objects without errors that
<Columns of type x cannot hold values of type y> - We can omit attributes or include new attributes in a new object without worrying about receiving errors like
<The number of columns in the derived column list must match the number of columns in table> - Single objects can be chained to another object’s property without receiving a
<Type is not supported>message
This flexibility has led programmers to take the concept of semi-structured data too far (and by tad I mean into planetary orbit). Therefore, in this blog we will share a few good practices for handling and constructing JSON models, and will go over some common bad practices that all of us should avoid like the plague.
Normalize your Data
We just launched our new application [coolName] and are using [sometool] to promote it. So we created a new account and every day we make an API call asking for a daily report. These are the results we received:
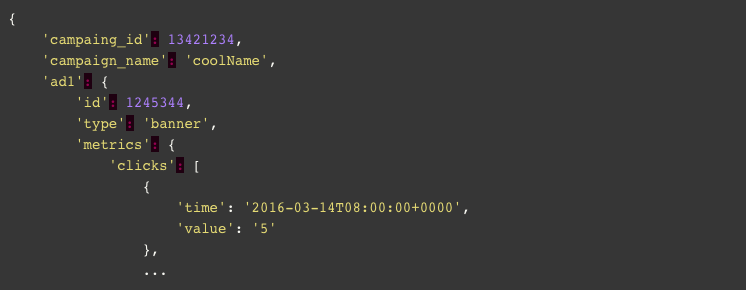
*Note that this is a partial result. As you can guess, there are more campaigns, with more ads and more metrics.
This is a valid JSON object that can easily be inserted into our sometool_analytics collection and many of us collect such documents exactly this why. So why is this bad? While this is a really simple JSON structure which is readable and describes the data well, if you want to calculate the sum of clicks from 2016-03-14 onwards you’ll end up having to process all the documents programmatically and your code will look something like this:
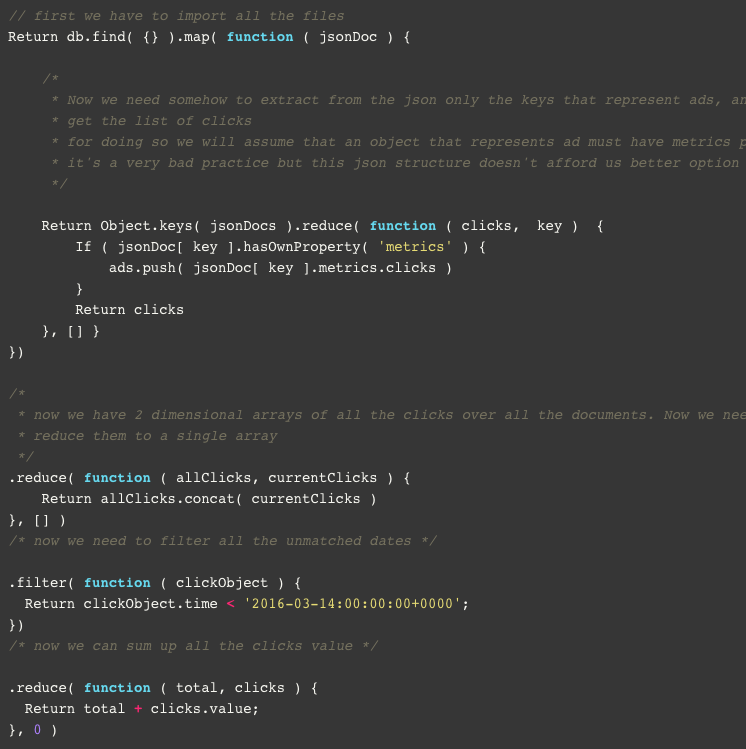
This code is plain fugly not to mention fragile. It assumes way too much about the structure of the given result. The moment [someTool] decides to change something in the structure of their result we can flush this down the drain. There is no reason you should insert such a block of code into your new application for such a simple question.
The best way to avoid such clumsy query code is to normalize your data into a structure which makes sense based on your data and queries. My rule of thumb, not only for data structuring but also for coding is, always to strive for an elegant solution where more is described with less. Let’s take a look at what this JSON is actually telling us. It says that we have “5” clicks, on the “2016-04-07T08:00:00+0000” for ad1 in the coolName campaign ( and some metadata ). Now that we know this, we can easily normalize these documents to a one level nested JSON object (we will cover this later) with 6 dimensions and one metric:
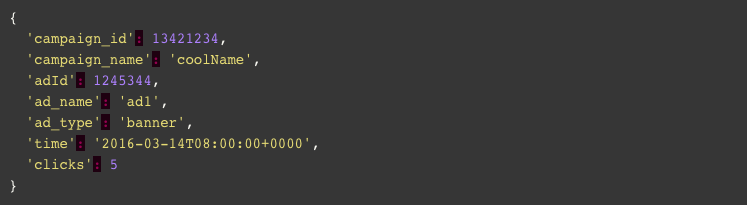
If the original result had included more metrics for the same date and ad we would have added them as an additional key-value pair, if it included more ads or other dates, we would have generated a new document per unique date and adId combination. Now, if you want to get the sum of clicks from the 2016-03-14 onwards, it’s as simple as:
 Keep your Data Flattened by Implementing Relations
Keep your Data Flattened by Implementing RelationsSo after promoting our application we now have enough users to discuss the next principle we should consider while working with semi-structure data.
To make the next examples simple let’s make our application a multi groups chat application (forgive me for the cliche).
Most of document-based databases set very high limits on the level of nesting. For example, Mongodb allow up to 100 level of nesting, if you know someone who uses it all or even close to all of it, please intro us! (oshri@panoply.io)
The first group was created and the first message sent so we document it into our groups collection:
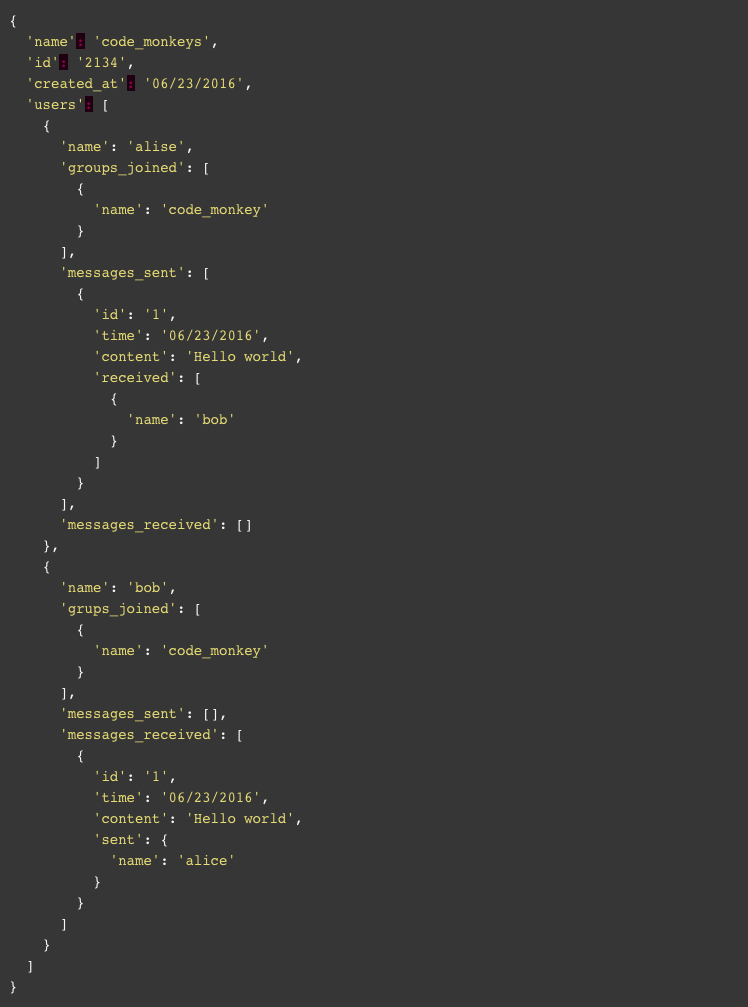
Now all we’ll ever want to know about our group is in a single document. Sounds amazing, or is it…?
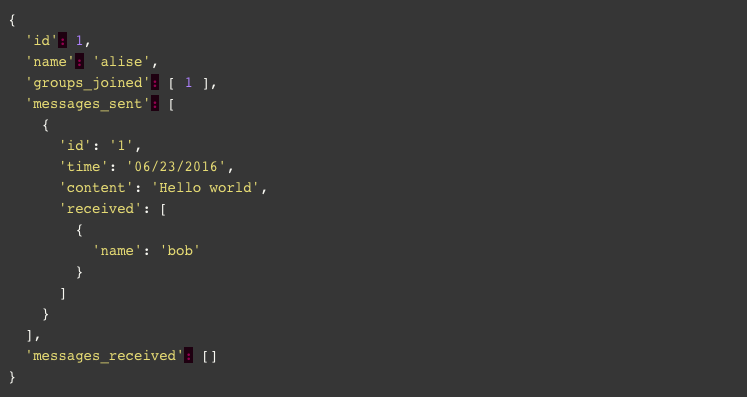
If our application will always need all the data regarding the group, then yes it’s amazing, but reality is a little different. Most of the queries performed by our application, this holds true for most of the applications out there, need only metadata or other specific data about the group, which means that each time we want to pull the group name we are pulling the entire document which will become larger and larger as more users join the group and more messages are sent. Currently the size of this JSON is 868 Bytes, and it was just created. Think about the process a user goes through when entering our application. We need to build the main page view that lists all groups and for this we will only need the groups names. We all know that building views should be super fast , but if we need to wait for the database to pull this giant document and we need to transfer it from our server to the client, then over the test of time we will fail. Many development teams encounter performance issues a couple of months after their launch and overcome it with caching mechanism, but frankly that’s like using a band-aid to treat an aneurysm, all of them end up reconstructing their databases at some point. So instead of attempting to fetch huge documents we should fetch only the name of the application or a small fixed size JSON. Nowadays with the popularity of NoSQL databases, the relationship principle, one of the core principles that guided every data architecture design process, got marginalized. Had we been building our application five or six years ago, we would have probably used RDBMS (relational database management system) database to store our data, which would not allow storing whole new lists of records as we did with users and “messages_sent” in the previous example. Instead we would use keys to define relations between our records and the structure of our data would look like this:
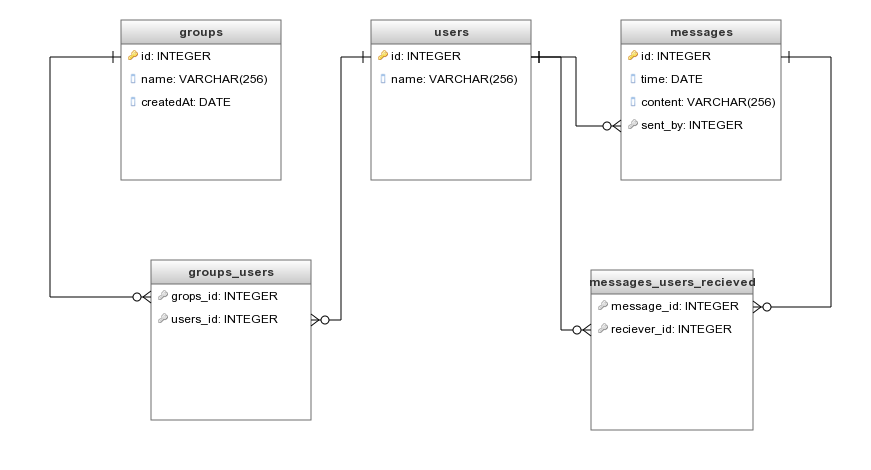
We can see that the group itself does not contain information on its users, but that there is a special table ‘groups_users’ that describe a many to many relationship and contain all the group and user pairs. When any user joins one of our groups we update the table with a new pair of user_id and group_id which acts as a foreign key to the users table and groups table. This way when we want to pull only the metadata of the group, we query the groups table and when we want the list of users belonging to a group we need only query the ‘group_users’ table to pull all the user ids paired with group id and use ids to query from the users table. As you can see that the same will happen for the list of users who received a specific message. Instead of listing the users on the message itself (which we wouldn’t be able to do even if we really were using RDBMS) we use a connection table. We have an additional relationship here , but it’s simpler and doesn’t require a special table. The relationship of messages to the users who sent them. This is called a one to many relationship because a message can have at most one sender. Therefore, instead of listing on the user object itself all the messages sent we query the messages table for all the messages where ‘sent_by’ equals to the user id and here ‘sent_by’ is defined as the foreign key. We will implement the same relations on our JSON data models.
So let’s start by separating the users from the groups:
groups:

users:
What we did here is create a new collection for users, and define users by group object and groups_joined on the user object as a typeof foreign key. You’re probably asking why I didn’t just create a third collection to store the connections like in RDBMS but instead set an array of relationships both in groups and users. The answer is that it could have, but we want to enjoy the best of both worlds. Therefore, I used the relationship concept to flatten my data and remove duplications and used the flexibility of JSON to store ids in an array with the ability to simply push new ids to the list. This way the operation of adding all users belonging to “code_monkey” will remain efficient even when the collections of groups and users becomes enormous. Now, our memory and network has been reduced to a crawl when we need only the group metadata , andwe can use a simple script to pull the list of users when we need them.
That said, there is an even better way to do this so let’s separate the messages from users :
Groups:
Users:
 Messages:
Messages:
Two birds with one stone. We use the relations to detach messages from the user object and remove the users from the messages themselves. Note that sent_by is not a list of ids but a single entry because the relation of a message to its sender is always one to many. The size of each object now is approximately 130 Bytes and all three together are roughly 400 Bytes, which is a 50% saving compared to the unflattened version of this data.
Conclusion
The ability to store and manage semi-structured data is powerful and storing and nesting object and arrays make it easier to process the data. Working without the constraints of strict schema and the ability to make changes frequently is gold in our agile world.
There are many databases that provide these abilities, some are more flexible and some are strict, but most of the power is in our hands. You saw how easy it is to misuse and create bad data structures. The examples above are not a construct of my imagination; I’m constantly working with data sources and I’ve seen more badly constructed JSON data collections then well constructed. The upside is that it is also easy to build elegant and efficient data collections and it makes all the difference in the long run.
In addition, you can learn about Redshift columnar storage and Redshift architecture here.



