Amazon Redshift is a very powerful data warehouse, optimized for analyzing massive amounts of data in a blink of a second, when configured right.
It’s a highly robust system, complete with features for configuring every step of the process with absolute visibility and control. But with all of these different configurations, it’s easy to get lost and make uninformed decisions. To that end, we’ve designed extensive benchmark tests to measure the performance of different Redshift features, and in this post I’ll introduce you to Redshift columnar storage write performance. This Redshift benchmark test doesn’t just measure its capabilities in isolation but also how a fully-fledged system would behave under different conditions.
Much has been said on the subject (see the following blogs and docs on Amazon and RJMetrics), but most of the tests we came across only compared Redshift’s COPY operation speed, disregarding the cost of serialization, compression and upload of the data into S3. For example, just testing if the Redshift COPY command is performing better with Gzipped data is meaningless if the compression time overweights the improvement to COPY performance. We wanted to test the entire data funnel – from raw in-memory data as it’s extracted from the source (or stream) to the end of the COPY process.
Another key difference for our tests is that we wanted to evaluate Redshift’s performance in micro-batches of medium-sized data sets, instead of huge ones that take hours to load. The reason for this is that in most practical use cases, when we want to stream data into Redshift at near real-time, we will incrementally load data in multiple small batches instead of one massive upload. We’re more likely to load 80GB per hour, or even a few GBs every few mins than 2TB once a day,
Here is what we set out to test:
- Data formats: CSV, JSON or AVRO?
- Compression: Yes or No?
- Parallelism: Single file or multiple files?
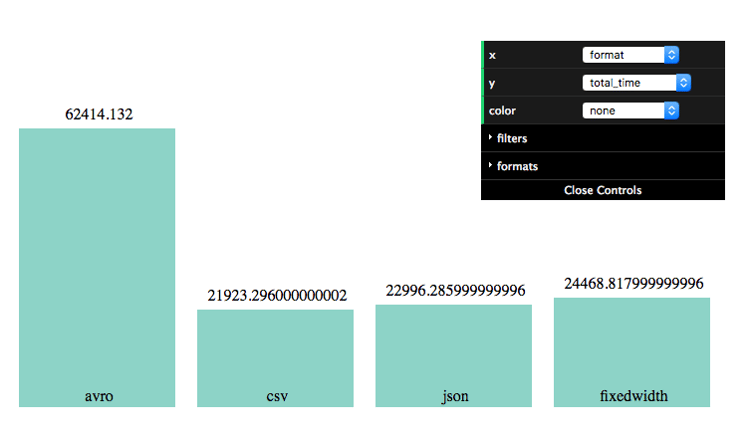
CSV, JSON or AVRO
TL;DR: Use CSV or Fixed-Width. Don’t use AVRO.
The simplest first choice to make is data format. CSV and JSON are already widely popular, while Apache Avro is a new binary serialization system with the great promise in storing well-structured data along with its schema.
Not surprisingly, CSV out-performs JSON in COPY performance. That’s easy to justify given the fact that JSON is much more verbose than CSV, resulting in larger files that are more difficult to parse. While JSONs are easy on the human eye, they’re highly redundant, repeating column names over and over again. This makes JSON extremely useful for cases where schema is inconsistent throughout the documents, but in the case of a highly-structured database like Redshift, it makes little sense.
However, using CSVs present several major challenges. Most notably, they are headerless (in Redshift, anyway) which means that there’s no consistent way to store schema, or just the list of columns, alongside with the data itself. Sure, we can use S3 Object Metadata attributes for that but these are limited to 2K, which isn’t nearly enough to capture the schema of 100+ column tables. So we have to resort to some other external storage, like a different S3 file or database, and keep the two in-sync.
What makes matters worse, is the fact that we can’t mix different columns under the same COPY operation with a manifest file, because each one might have a slightly different columns list. This might not sound that bad, but when considering real-life applications, you’re likely to want to re-copy old files sometimes, while some of the columns may have been changed, or we might want to bundle several different files, each with its own list of columns, and copy them all at once.
Bottom line, CSV is still vastly superior to JSON and therefore worth going through the trouble. But AVRO is inferior to both. To be honest, this was a big surprise, because AVRO is designed to be the best of both worlds: well-compact plus with isolated self-contained schemas. Especially given the fact that it’s a binary format and results in file sizes smaller than CSVs. But not only does it deliver worse COPY performance, it’s also far more expansive to serialize which makes it entirely unusable for realistic use-cases at this point. However, I’m sure that the idea behind Avro, once materialized and implemented correctly in Redshift, will become the holy grail.
One last thing, a little known secret is the option of using fixed-width data columns instead of a delimiter like in the CSV option. This results in a file that’s slightly less compact than CSV, unless compressed, but is much easier to parse through. Fixed width resulted in the same, or better performance compared to CSV.
Compressed or Uncompressed
TL;DR: Always Gzip the data. Avoid blobs of text which aren’t useful for analysis anyway.
The question of compressing the dataset, is far more complex. There’s no simple answer because it really depends on entropy of the data: the more random it is, the less compression.
Instead of trying to control the output compression ratio, we decided to use realistic datasets. In this example, we used a public database from Data.gov showing the leading causes of death by sex and ethnicity in New York City since 2007. We later ran the same test on some of our customer’s data (with their approval of course), and reached similar relative results.
If the dataset is comprised mostly of numeric measures, with a high variance, it’s likely to be poorly compressed. Same goes for large text blobs, which are arguably not very useful in analytical queries anyway. These types of datasets will result in a big investment of compression time, while not significantly reducing the data size or improving performance. The more repetitive the data, the better compression you’ll get. So datasets that include mostly low-cardinality columns, like city names, or categories, would be ideal for compression.
However, for most uses cases, it’s almost always a good rule of thumb to GZIP the data. Using real-life example data, we’ve seen 10%-30% performance boost.
For AVRO, we couldn’t really test the compression itself separately from the serialization as AVRO handles both in parallel.
Single File or Multiple Files
TL;DR: Use 4-6 files per node with a manifest file
There are three ways you can deliver data files to the COPY command: You can use a single big file, you can use multiple files with a common prefix and pass that prefix to the COPY command, or you can use a separate manifest file to list all files from different locations.
A poorly documented fact is that the normal non-manifest COPY command, always uses prefixes, not exact files. This means that if you have two files named data.csv and data.csv.old in the same S3 folder, trying to COPY the first one will result in both being copied, because in essence, you’ve tried to COPY all files with the data.csv prefix. That’s one reason why we suggest to always use a manifest file.
Another good reason to use manifest files is book-keeping: it allows you to re-run COPY operations, and check retroactively what went wrong. The extra cost of creating the manifest file is negligible in most use-cases.
When you send a single file to a COPY command on the leader Redshift node it gets broken down into smaller sub-ranges that are fed down to the individual Redshift nodes. Similarly, when you’re sending multiple files, all of these files will be fed down to the nodes in the same manner, resulting in smaller ranges, but more files, per node.
Using multiple files allows individual Redshift nodes to handle separate files in isolation, resulting in a significant performance improvement. We can see that as we add more files we gain increasingly smaller performance improvements. In parallel, the compression effectiveness per file worsen, resulting in larger files and longer upload times. So we don’t want to over-do it. While it’s not apparent specifically from this test results, we’ve identified the sweetspot to be at around 4-6 files per node, which is slightly lower than the 1-file per slice recommended by Amazon.
AVRO is weird again – having more input files didn’t affect the write performance at all.
Data Size
In terms of data size, we’ve decided to do something different with this test. In most benchmarks out there, it’s common to see relatively large datasets, in the range of tens or hundreds of GBs being copied at once. While these are perfectly good ways to measure the Redshift COPY performance, our use case is a bit different: we’re aiming to perform many small inserts in high frequency. Therefore the test covers realistic incremental data loads.
An important aspect of any data platform is data streaming: the ability to push data in near-real-time and make it available for analysis. A common use case is tracking users on page, payments or installs of an app as they’re taking place. Traditionally, these cases were left unresolved in Data Warehousing platforms. The paradigm of the past few decades (that’s right, decades!) was to have a periodic ETL process that was able to run in a predefined daily time-window, during which most analysis operations were locked while all of the data was flowing in. In a day of agile and continuous deployment, this notion seems ancient, but unfortunately it’s still popular.
Inhouse we’re using micro-batches to stream data in as it arrives. There are several ways this can be done, most simply, using Kinesis Firehose with an orchestration layer for backing off when analysis queries comes in. This topic is outside the scope of this post, but we’ll cover it in depth in one of our future posts.
In the meantime, we wanted to measure how the performance scales as the data grows, both vertically in number of rows, but also horizontally, in number of columns.
One small note is that if you’re looking to also use micro-batches and perform many tiny inserts throughout the day, you should probably turn off the ANALYZE and COMPUPDATE phases of the individual COPY operations, and run them manually once a day or so. This will significantly improve the performance of your COPY commands. We’ve turned both of these options off for this Redshift benchmark test.
Conclusion: Redshift Benchmark Test
Loading data into Redshift, using small fast batches can be very fast, when configured correctly. In fact, you can achieve almost real-time data ingestion, with a latency of just a few minutes. The best rule of thumbs at this point in time is to load data with several compressed fixed-width/CSV files with a manifest.
There are many other topics that are not covered in this post. For example: the performance of different table compression schemes within Redshift, or the different implications of sortkeys and dist styles on the loading performance. There’s also the subject of handling upsert operations along with history tables, which further complicates things.
The tricky bit is that Redshift is constantly evolving. New features are deployed every week, so you should probably keep track of the changes, and are welcome to follow our blog for new updates & benchmark tests.
Would you like to learn more about Redshift cluster? Check: Redshift cluster.



