One of the main goals of this blog is to help developers and data architects, just like us, with their Amazon Redshift operations, including Redshift security. Starting from a full comparison with Google BigQuery, explaining how to load Google analytics data into it and perform analysis using Tableau, all the way to providing you with tools such as PGProxy, which can help you load balance queries between multiple Redshift clusters, this article may extend your know-how on Redshift and help you do your job much better.
When building a new system, our urge is to do the magic, make it work, and gain the user appreciation for it as fast as we can. Security is not the first consideration. However, as the system grows, and especially as the amount of data we store grows, the realization that there’s an asset that needs protecting becomes abundantly clear.
This guide will help you continually encrypt your data loads to Redshift and make sure your information is safe.
About Amazon KMS for Redshift Security
Before getting into the step-by-step details, note that we are going to use one of Amazon’s main encryption tools, the AWS Key Management Service(KMS). This service allows for the creation and management of encryption keys. It is based on the envelope algorithm concept, so it requires two keys for encrypt/decrypt operations –– a data key to encrypt the data and a master key to encrypt the data key.
Using Amazon Unload/Copy Utility
This Amazon Redshift utility helps to migrate data between Redshift clusters or databases. Using it we can also move the data from Redshift to S3. Then we will use KMS to encrypt the data and return it to Redshift. (Image source: GitHub)
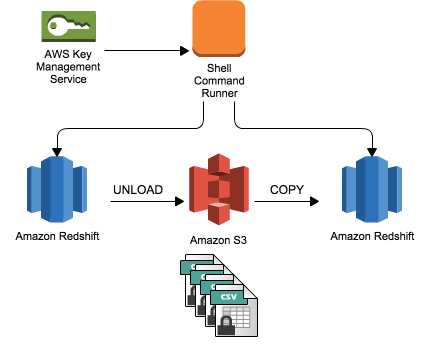
This is planned for use as a scheduled activity for instances running a data pipeline shell activity.
- Connect to Redshift: We use PyGreSQL (Python Module) to connect to our Redshift cluster. To install PyGreSQL on an EC2 Linux instance, run these commands:

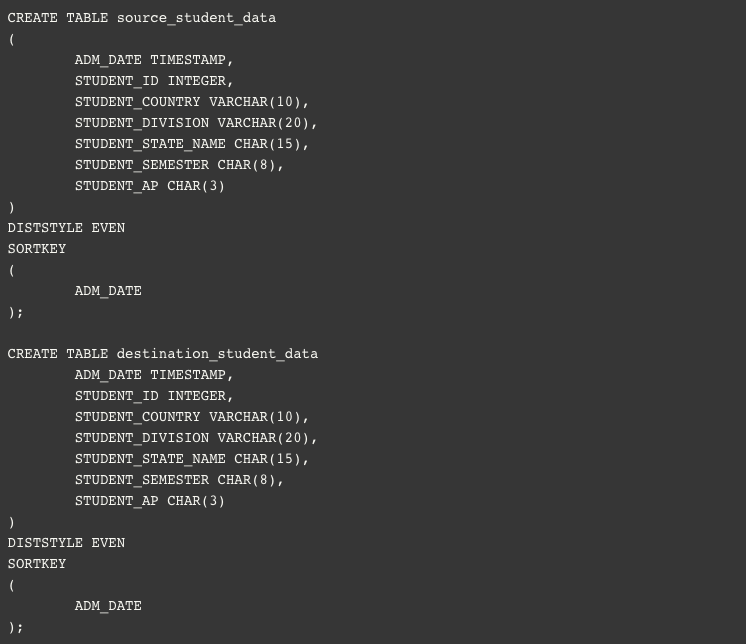
- Next, we need to create two identical tables in Redshift, one for source redshift and another for destination redshift. In source redshift we will create a table name “source_student_data”, and in destination redshift we will create a table name “destination_student_data”.
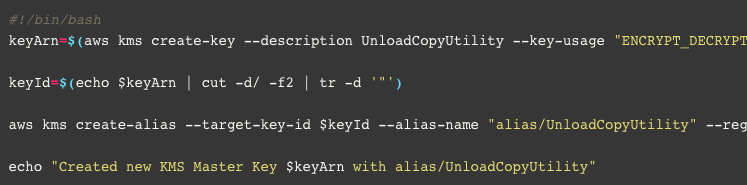
- Because we are going to encrypt our Redshift data with KMS, we need to create a KMS master key. In this step, we will create it using the following script, named ‘createkmskey.sh’:
- After creating a KMS master key, it’s time to encrypt our password. We will write a bash script named encryptvalue.sh, which will generate a Base64-encoded encrypted value that we will use in our configuration file in the next step. To create “encryptvalue.sh”, run the following commands:
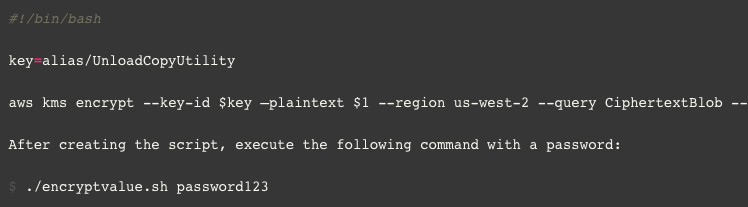
The output will resemble the following:
DqPLC+63KJ29llps+IZExFl5Ce47Qrg+ptqCnAHQFHY0fBKRAQEBAgB4lGPveByOeoYb7fiGRMRZeQnuO0K4PqbagpwB0BR2NHwAAABoMGYGCSqGSIb3DQEHBqBZMFcCAQAwUgYJKoZIhvcNAQcBMB4GCWCGSAFlAwQBLjARBAwcOR73wpqThnkYsHMCARCAJbci0vUsbM9iZm8S8fhkXhtk9vGCO5sLP+OdimgbnvyCE5QoD6k=
Now, we need to copy this value and insert it into our configuration file.
- We are going to use a Python script to automatically unload/copy our Redshift data, so we need to provide information beforehand. In this step, we will create a configuration file named ‘config.json’, where we will provide the Redshift cluster endpoint, database name, AWS access key, and S3 bucket, as well as the Base64-encoded password created in the previous step.
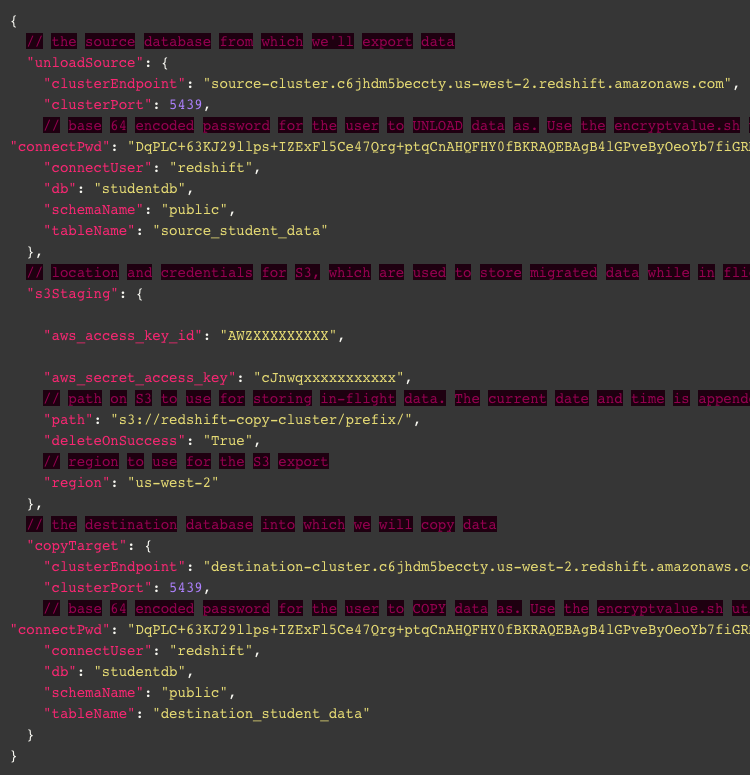
- We are using a Python script name, “redshift-unload-copy.py”, which will unload the source data from Redshift, then encrypt the data with the KMS master key and upload to S3, and finally copy the encrypted data from S3 to the destination Redshift cluster.
$ python redshift-unload-copy.py s3://redshift-copy-cluster/config.json us-west-2
Using AWS Lambda
This solution builds an automatic pipeline that creates a KMS master key, uploads encrypted data to S3, and copies the encrypted data back to Redshift. Next, we’ll use Lambda to continuously encrypt newly incoming data.
At the initial stage, Lambda receives an S3 notification. Based on the file prefix, Lambda receives the bucket and the key, then builds the copy command that will run in the destination Redshift cluster. To make the Lambda function idempotent, it verifies the file has not already been copied before executing the ‘COPY’ command.
To implement this solution, we need to do the following things:
1- First of all, download the source file
2- After downloading the zip file, unzip it, and edit the parameters of the ‘copy.py’ script’ file according to these requirements:
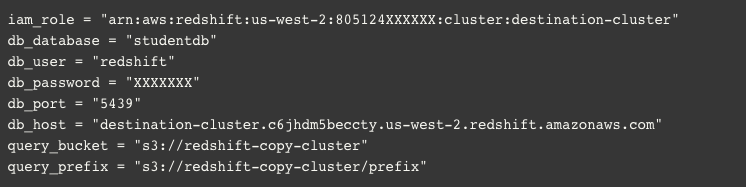
3- Once the ‘copy.py’ file is edited, zip the whole folder again.
4- Now, in the AWS console, go to AWS Lambda. and create a function.
5- Click Create a Lambda Function to display the next page.
6- Select Blank Function to configure the triggers.
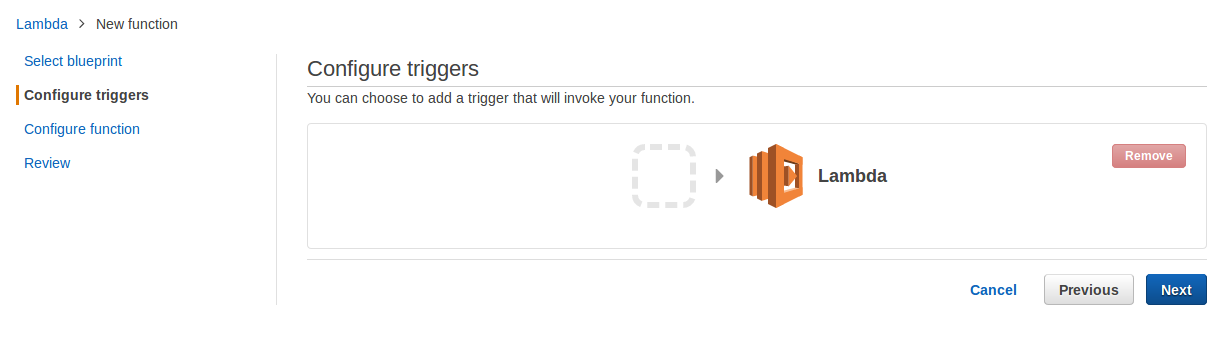
7- Click Next.
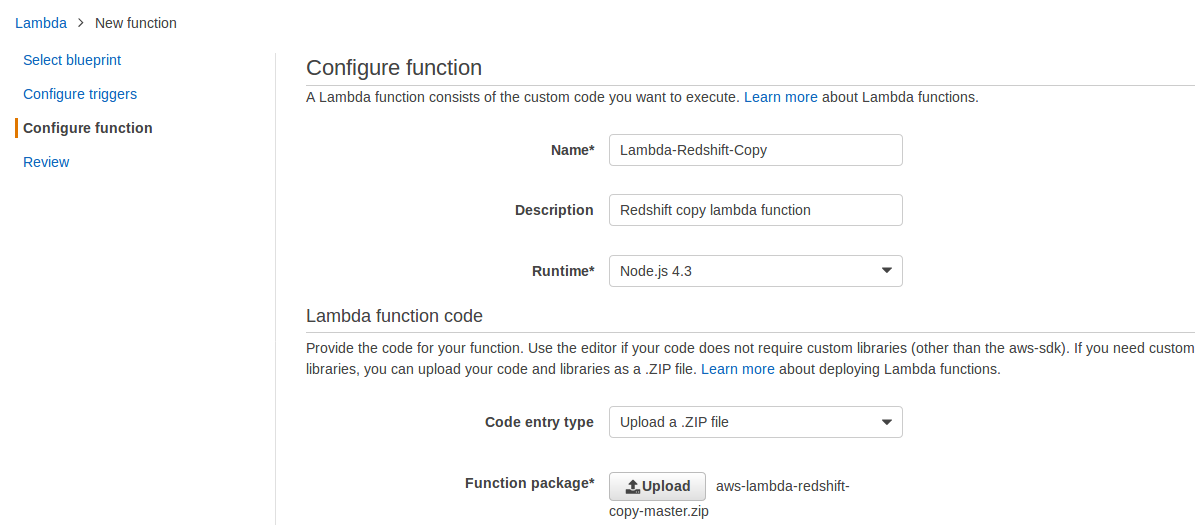
8- On this page, specify the Name, Description and Runtime environment. For our use case, the Runtime environment will be Python 2.7. From the Code entry type drop down list, select Upload a ZIP file and select the zip file we created earlier).
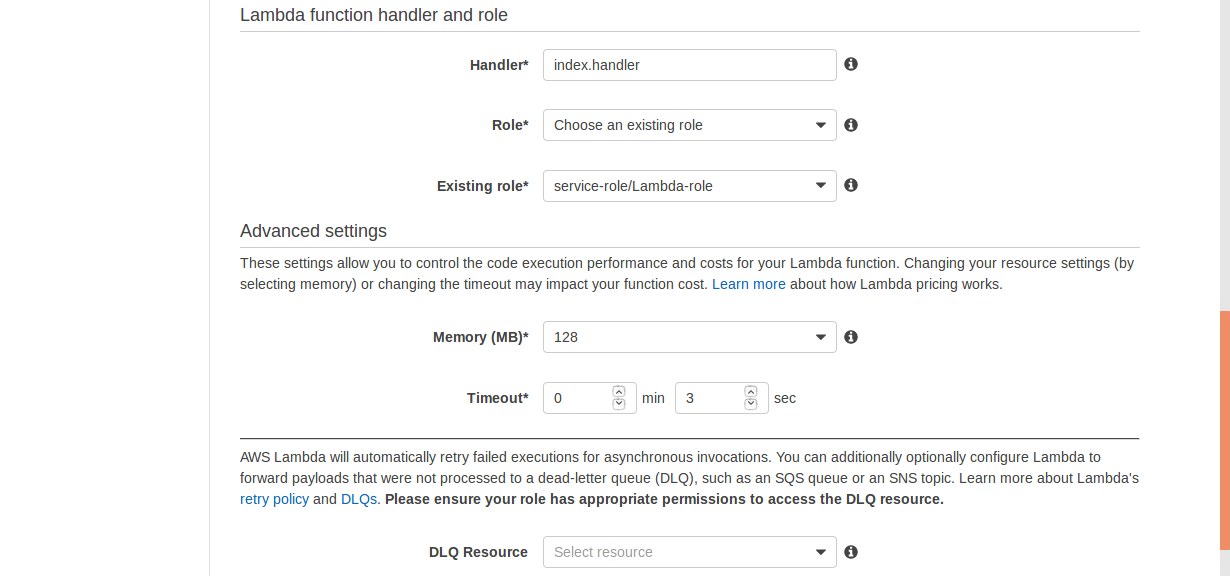
9- Provide the handler, role and existing role information, and click Next.
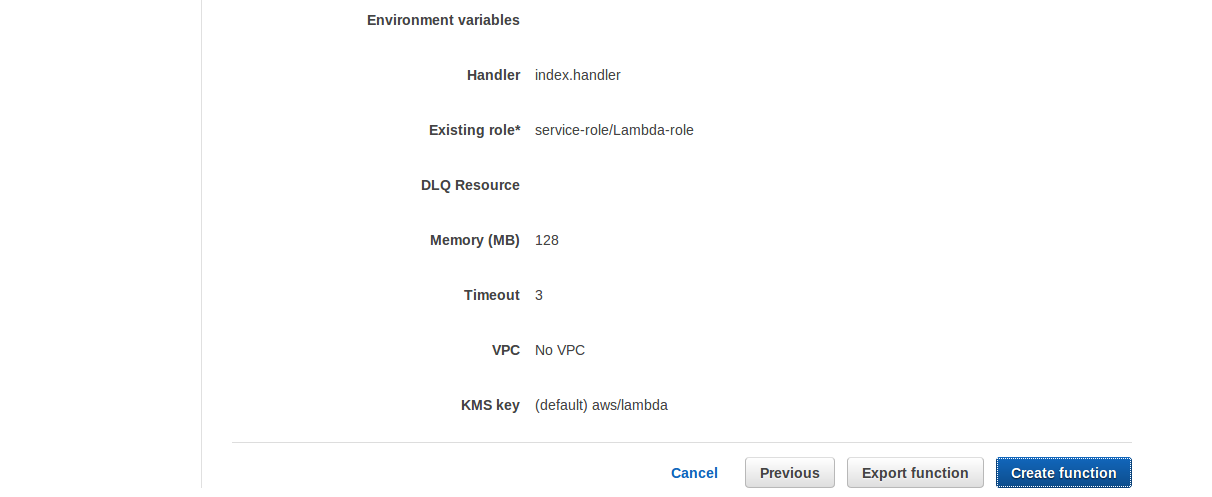
10- Click Create Function to create the function in Lambda.
The function runs the copy query to load the data into the Destination Redshift Cluster upon receiving any encrypted data in the S3 bucket.
This solution can be used to replicate real-time data from one Redshift cluster to another. In that case, we need to configure an event trigger in the S3 bucket. For details on configuring an event trigger with S3 bucket, we can follow this link.
Final Note on Redshift Security
Using own KMS customer-managed keys allow us to protect the Amazon Redshift data and give full control over who can use these keys to access the cluster data. It is worth mentioning that with AWS services KMS and S3, encryption of your data loads is provided without any additional charge, though KMS has a limited free tier offer up to 20,000 requests per month.
In the past, we had to meet our security professionals and ask them to integrate security into our data repositories, in large and complex environments we still do. However, we can also follow such guidelines which enable us, the data architects, to ensure the bare minimum when it comes to running our data solutions on the cloud, especially as one researches relevant topics including Redshift security. I hope this solution will help you do your work in a safe and secure data environment.



