Poorly designed databases can cause many problems, including a waste of resources, difficult maintenance, and faulty performance. That's why having a great database schema design is a crucial part of effective data management.
"Great database schema design" is certainly easier said than done, though. Since a given domain or business problem can be modeled in infinitely different ways, it stands to reason that there are comparatively fewer ways of doing it correctly.
That's why it's so important to learn principles and best practices when it comes to database schema design. And that's exactly what this post is about.
We'll start with some basics, explaining what a database schema is and why it's important. Then, we'll talk about how you create schemas in practice. Last but not least, we'll get into the practical part of the post, in which you'll see an example of database schema design. Let's dig in.
Database schema: The fundamentals
Before you roll up your sleeves to design a database schema, you must have a solid understanding of what that even is and why it matters so much.
What is a database schema?
A database schema, in a nutshell, is the way a given database is organized or structured. Not all types of databases make use of a rigid schema—NoSQL databases such as MongoDB come to mind. However, the ones that do will require you to have a structure in place before you start adding data to your database.
Why is a database schema important?
Relational database systems—such as Postgres or MySQL—rely on having a schema in place so you can work with them. So that's the first reason a database schema is important: you literally can't have a database without one.
Also, a sloppy design can give you headaches. If your schema isn't structured in an optimal way—e.g., it doesn't follow normalization—that might result in duplicated or inconsistent data. On the other hand, it's possible to get to the other extreme where your queries become slow.
To sum it up, database schema design is essential because you want your databases to work as efficiently as possible.
How do you create a database schema in practice?
Having explained what a database schema is and why it's important, let's now walk you through how you can design one.
The tools of the trade
There are mainly two tools you'd use to create a database schema. The first is an RDBMS, or a relational database management system. Examples of RDBMSs include SQL Server, MySQL, and PostgreSQL.
The second and most important tool is SQL (structured query language). This is the language we use to define the tables, columns, indexes, and other artifacts in our database.
Sure, there's nothing wrong with using diagramming programs—or even pen and paper—to define the overall design of a database. But in order to implement the database in practice, you'll need a real RDBMS and SQL.
Database schema design: A real world example
For our database schema design example, we'll use PostgreSQL as our RDBMS. The demo database schema we'll design will be for a fictional bookstore.
Let's start by creating a schema called bookstore and a table called genres:
CREATE TABLE bookstore.genres ( id SERIAL PRIMARY KEY, "name" varchar(255) NOT NULL UNIQUE, "description" varchar(255) NOT NULL )
The snippet of code above, besides defining a schema, also creates a table in it, which we call genres. The genres table has three columns:
id, which is a unique identifier for each genrename, which is a unique name for each genre- and
description, which is a brief, optional description
A bookstore certainly needs information about authors, so let's create a table for that as well.
Creating a table for authors
CREATE TABLE bookstore.authors ( id SERIAL PRIMARY KEY, "name" varchar(255) NOT NULL, "bio" varchar(500) NOT NULL )
With the authors table, we can manage data about authors, using three columns:
- again, a numerical, auto-incremental
id, which serves as a unique identifier - a
name—this time without a "unique" constraint, since it's perfectly fine for two authors to have the same name - and a
biography
Creating a table for books
We're now getting closer to being able to store the books themselves. Let's create a table for that:
CREATE TABLE bookstore.books ( id SERIAL PRIMARY KEY, title varchar(255) NOT NULL, description varchar(255) NOT NULL, ISBN char(13) NOT NULL, genre_id INT NOT NULL, CONSTRAINT fk_genre FOREIGN KEY(genre_id) REFERENCES bookstore.genres(id) )
The table books is more involved than the previous ones. Besides the usual unique numerical identifier, a display column—in this case, "title" instead of "name"—and a description, this table also contains a column called ISBN (an International Standard Book Number) and, most interestingly, a foreign key constraint.
In a nutshell, foreign keys are what allow us to connect tables together. In this case, the column genre_id in the table books references the columns id from the table genres. That way, it's possible to express the relationship between those two entities. To use the jargon, we've defined a one-to-many relationship. In other words, a single genre can have one or more books assigned to it. On the other hand, there's no way to assign more than one genre to a book since the genre_id column can only point to a single row at a time.
Connecting books and authors
You might have noticed that our table books doesn't have any relationship to authors. Couldn't we just include another foreign key in the table, connecting it to authors, the same as we did for genres? Sure, that would be possible. However, remember that our requirements state that books can have more than one author.
So an author might be associated with many books, while a book might have more than one author. That's what we call a many-to-many relationship. There's no way we can design that relationship by adding a column to the authors or to the books table.
Instead, our solution here is to create a third table, which will hold foreign keys to both authors and books:
CREATE TABLE bookstore.books_authors
( book_id int REFERENCES bookstore.books (id), author_id int REFERENCES bookstore.authors (id), is_main_author BOOLEAN NOT NULL DEFAULT false, CONSTRAINT bill_product_pkey PRIMARY KEY (book_id, author_id) );
In this third table, we reference both author_id and book_id. We also have an extra column, is_main_author, of type boolean—that is, it can be true or false and indicates whether a given author is the main author of the book specified in the relationship.
That's a lot to keep track of (and we've just scratched the surface!), so here's how all those tables fit together:
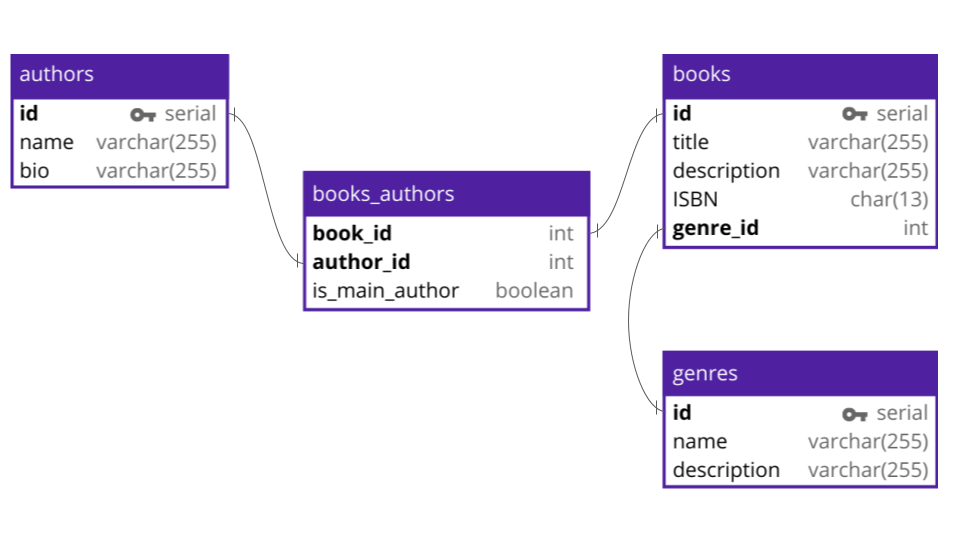 With the schema we designed so far, we're able to store and manage information about a simple bookstore. Keep in mind that a real-world schema for a bookstore would probably be much more complex. However, our example should be enough to give you an idea of what is involved in creating a database schema.
With the schema we designed so far, we're able to store and manage information about a simple bookstore. Keep in mind that a real-world schema for a bookstore would probably be much more complex. However, our example should be enough to give you an idea of what is involved in creating a database schema.
Database schema design: What comes next?
In this post, we've offered you an intro to the concept of a database schema. You've learned what a schema is, why it's so important, and how one is created. Then, we've walked you through an example of designing a basic yet functional database schema for a fictional bookstore.
From deciding which tables contain which data to how they connect, there's a lot that goes into creating an efficient database schema. And there's nothing more irritating than creating a complex schema and then having to enter all that info into your data warehouse software.
That's where Panoply comes in. Along with providing code-free data connections and managed storage, Panoply automatically detects your database schemas so the data you ingest is right where you expect and ready for analysis.
To learn more about how Panoply makes working with your data easier, book a personalized demo.



